基于正交基的多视图迁移谱聚类
王丽娟,张霖,尹明,郝志峰,蔡瑞初,温雯
(1.广东工业大学 计算机学院,广州 510006;
2.广东工业大学 自动化学院,广州 510006;
3.汕头大学,广东 汕头 515063)
聚类是一种无监督的大规模数据分析算法,在过去的几十年中,许多经典聚类算法被提出。经典的聚类算法包含但不限于标准谱聚类[1](Spectral Clustering,SC)、稀疏子空间聚类[2](Sparse Subspace Clustering,SSC)和低秩表示[3](Low-Rank Representation,LRR)等。尽管这些算法取得了较好的成果,但其仅考虑单视图数据,忽略了来自不同的特征集或异构源的信息。
在现实生活中,目标对象通常由来自不同视图的信息表示,即数据可以由多个不同的特征集或多个异构源来描述。例如,一幅图像可用像素强度、梯度方向直方图(Histogram of Oriented Gradient,HOG)和局部二值模式(Local Binary Pattern,LBP)等不同的图像特征来描述。在生物医学研究中,不同细胞的化学结构和反应都可以用来代表某种药物,而序列和基因表达值可以在不同方面代表某种蛋白质[4]。多视图数据提供来自不同视图的丰富底层信息,只有所有视图结合在一起才能准确、真实地表示对象。为了充分利用多视图信息,近年来研究人员提出了许多多视图聚类算法[5-7]。
考虑到多个视图特征共同描述同一数据,因此不同视图之间应该存在许多共享信息。如何将多个视图集成在一起,从不同的视图中提取一致的底层信息,是多视图聚类需要重点解决的问题。基于此,研究人员提出一些有效的多视图聚类算法,主要分为图学习(或图融合)和谱学习,图学习通过学习一致性图对多视图数据进行聚类。文献[8]通过学习多个单一图,继而将学习到的多个图集成到具有k个分量的全局图中。文献[9]利用拉普拉斯矩阵上的秩约束学习一致性图,无需后处理步骤直接从图本身获得聚类分配结果。谱学习通过直接学习或构建公共子空间学习一致性表示,从而获取多视图数据之间的一致性信息。例如,自适应加权Procrustes[5](Adaptively Weighted Procrustes,AWP)利 用 PA(Procrustes Analysis)技术从谱嵌入中恢复了一致性聚类指标矩阵。文献[6]提出一种结合非负嵌入和谱嵌入的多视角谱聚类(NESE)算法,该算法在统一框架中同时学习非负嵌入和谱嵌入,其中非负嵌入直接揭示了一致的聚类结果,从而提升聚类性能。文献[10]表明,挖掘多视图数据之间的底层一致性,对于提高多视图聚类性能非常重要。
综上所述,挖掘多视图数据之间的底层一致信息是一项至关重要和具有挑战性的工作。本文提出一种基于正交基的多视图迁移谱聚类(Orthogonal basis-based Multiview Transfer Spectral Clustering,OMTSC)算法。OMTSC 算法同时学习每个视图的聚类分配矩阵和特征嵌入,并将聚类分配矩阵分解为共享正交基矩阵和聚类编码矩阵。其中正交基矩阵包含一组潜在的聚类中心,即每个多视图样本可以有效地分配给多个不同权重的类。同时,引入基于二部图的协同聚类来控制和实现多视图之间的知识迁移,发现多视图之间的一致性信息,维护各个视图的特征流形信息。在此基础上,通过从正交基矩阵和特征嵌入迁移知识来获取每个视图聚类任务的聚类编码矩阵,将正交基矩阵和加权聚类编码矩阵相结合学习多视图聚类分配矩阵,从而得到最终聚类指标。
本节将介绍文中用到的符号以及迁移学习和单(多)视图谱聚类的相关工作。
1.1 矩阵表示
在本文中,X={X(1),X(2),…,X(V)}表示V个视图的数据矩阵,表示第v个视图的数据矩阵,其中,dv表示第v个视图的特征数目,n表示样本总数目,对应于第v个视图的第(i,j)个元素,I和1 表示对角线元素为1 的单位矩阵。
1.2 迁移学习
迁移学习[11-13]的目的是通过迁移源领域的知识来提高目标学习者在目标领域中的表现,其在文档分类[11]、情感分类[14]、协同训练[15]等许多数据挖掘领域中都取得较好的效果。协同训练考虑在只有一小组标记样本的情况下,通过迁移相关知识给无标记样本,从而提高学习算法的性能。
文献[16]基于协同训练提出一种双视图谱聚类算法,即二部图协同聚类。该算法通过在两个视图之间迁移相关知识,达到提升多视图聚类性能的目的。二部图的相似矩阵定义为:

其中:A∈ℝd×n为数据矩阵,d和n分别表示特征个数和样本个数。
对应的图拉普拉斯矩阵定义为:

其中:D1=diag(A1);
D2=diag(AT1)。
二部图协同聚类的目标函数表示如下:
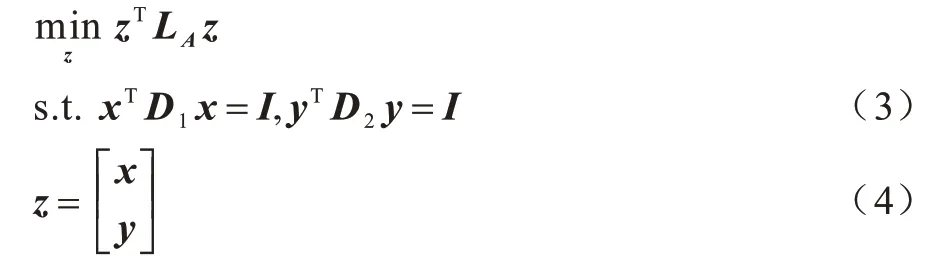
其中:向量x为特征嵌入;
向量y为样本嵌入。可将式(3)转化为:
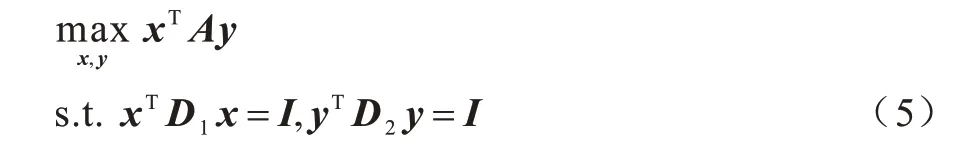
1.3 正交基聚类
文献[17]提出一种无监督特征选择算法,即同时正交基聚类特征选择(Simultaneous Orthogonal basis Clustering Feature Selection,SOCFS)算法。该算法旨在利用目标矩阵通过正交基聚类获取投影数据点的潜在聚类中心,继而引导投影矩阵选择判别特征。给出特征权重矩阵G∈ℝd×m,目标矩阵K∈ℝm×n,SOCFS正交基聚类部分表示如下:
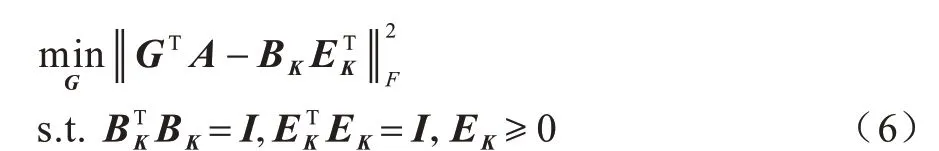
其中:目标矩阵K可直接对投影的数据点GTA进行聚类。因此,允许K拥有额外的自由度,将其分解为正交基矩阵BK∈ℝm×c和聚类指标矩阵EK∈ℝn×c,即K=BET。施加在BK上的正交约束保证了BK的每一列是独立的,即BK由投影的数据点GTA的正交基构成。此外,BK的列可以看作是相应聚类中心的方向。施加在EK上的正交和非负约束使得EK的每一行只有一个非零元素。因此,可以利用K=BET来寻找潜在的聚类中心,从而更好地分离聚类。
1.4 单视图谱聚类
本节主要介绍通用的单视图谱聚类算法[15]。假设存在n个数据点,需将其分成c个类。谱聚类第1 步是构造一个无向相似图G={X,W},其中,X∈ℝd×n为顶点集,W∈ℝn×n为对应的相似矩阵,W中的元素wi,j定义为每对顶点(xi,xj)的相似性,可通过式(7)计算:
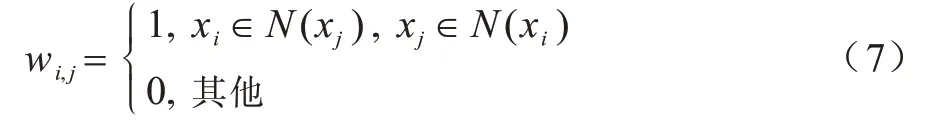
其中:N(x*)为搜索x*的k近邻函数。
通过求解一个特征值分解问题得到原始数据的谱嵌入,即:

其中:P∈ℝn×c为聚类分配矩阵;
L∈ℝn×n为图拉普拉斯矩阵,可由L=I-W定义。求解得出的最优P是L最小的k个特征值对应的特征向量。最后,对聚类分配矩阵P进行k-means 聚类,返回k-means 的聚类结果作为最终指标。
1.5 多视图谱聚类
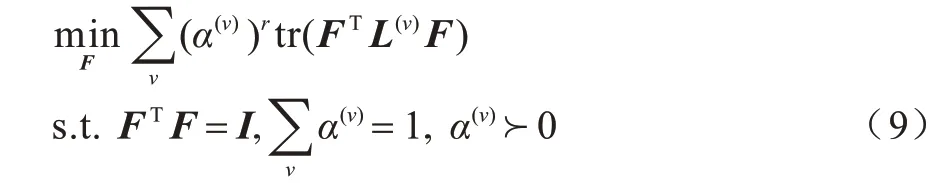
其中:α(v)是一个非负归一化系数,可以反映不同视图的权重;
r是一个标量,用于控制权重在不同视图上的分布;
L(v)为第v个视图的图拉普拉斯矩阵;
F为求解得出的一致性嵌入,即多视图聚类分配矩阵。
在实际应用中,数据往往由多个不同的特征集或多个异构源来描述,即多视图数据。单视图谱聚类[15,20-22]并不能独立地处理多视图数据,并且聚类性能一般。为解决这一问题,近年来研究人员在单视图聚类的基础上提出多视图聚类算法。多视图谱聚类通过最大化多视图一致性来提高聚类性能。因此,如何最大化多视图一致性成为一个关键问题。
现有的多视图聚类算法[5-7]通过学习一致性嵌入或者一致性图来挖掘多视图一致性,但其存在不足之处:一是多视图一致性信息挖掘不充分;
二是无法有效地平衡不同视图的质量差异。本文OMTSC算法与现有算法的不同之处在于:OMTSC 分解一致性表示,即聚类分配矩阵,分别学习正交基矩阵和聚类编码矩阵。一方面,正交基矩阵可以捕获并储存多视图一致性;
另一方面,聚类编码矩阵通过加权融合,可更好地平衡不同视图的质量差异。并且OMTSC 算法利用二部图充分挖掘多视图数据的一致性和多样性,通过多样性提升一致性的学习性能。
本文工作的主要贡献如下:
1)提出一种基于正交基的多视图迁移谱聚类(OMTSC)算法。该算法在一个统一框架中学习聚类分配矩阵和特征嵌入。
2)聚类分配矩阵可分解为正交基矩阵和聚类编码矩阵。正交基矩阵保留潜在的聚类中心,并捕获多视图数据之间的一致性信息。
3)OMTSC 算法学习特征嵌入,借助其多样性并最大限度地优化多视图一致性。
为有效地挖掘多视图数据之间的一致性,本节提出基于正交基的多视图迁移谱聚类(OMTSC)算法。
2.1 多视图迁移谱聚类
OMTSC 算法沿用文献[17]采用正交基聚类发现潜在的聚类中心的思想,可将每个视图的聚类分配矩阵P分解为两个子矩阵,即共享正交基矩阵B∈ℝc×c和一个聚类编码矩阵E(v)∈ℝn×c。聚类分配矩阵可表示为P(v)=E(v)B,则传统多视图谱聚类可以演化为以下形式:
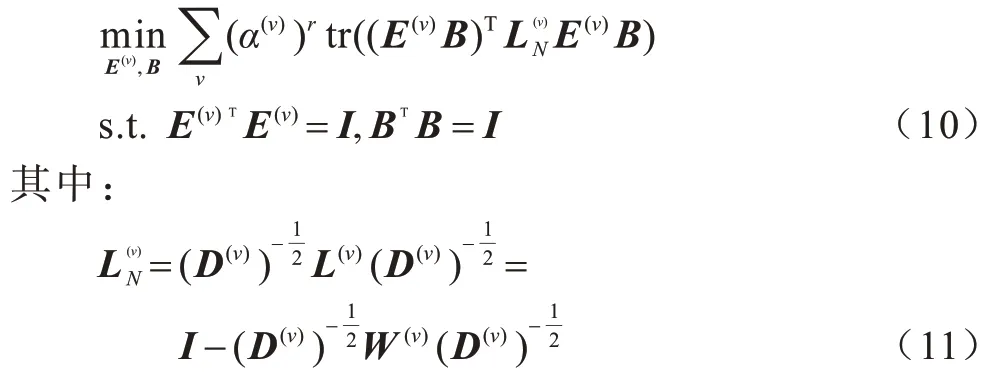
其中:为第v个视图的归一化图拉普拉斯矩阵;
W(v)为第v个视图的相似矩阵;
D(v)=diag(W(v)1)。对聚类编码矩阵施加的正交约束促使E(v)的每一行只有一个元素。E(v)的每一行元素选择了B中的一行,这是一个将多个样本分配给不同聚类的过程。对正交基矩阵B施加的正交约束促使B的每一行相互独立。因此,本文利用B来细化潜在的聚类中心,从而捕获多视图数据之间的一致性信息,以获得更好的聚类性能。
OMTSC 算法为更好地学习多视图一致性,通过优化学习到的正交基矩阵B,并致力于进一步细化潜在的聚类中心。本文为每个视图构建对应的特征嵌入,其中k为降维数目。受文献[16]采用基于二部图协同聚类来控制和实现两个任务之间的知识迁移的启发,OMTSC 引入二部图协同聚类,并将多个视图连接在一起。不同于二部图协同聚类算法,OMTSC 适用于多视图聚类任务。考虑到B是多视图数据的共同聚类中心,它可以在多个视图之间进行迁移。B可将在上一视图捕获到的一致性知识迁移到下一视图,从而促进下一视图的学习和优化。同时,OMTSC 通过从正交基矩阵B和特征嵌入A(v)迁移知识来获取并优化每个视图聚类任务的聚类编码矩阵E(v)。其相关模型如下:

在多视图之间迁移的正交基矩阵B,基于多视图数据一致性原则,可以促进一致性信息的学习,多视图谱聚类任务可以从共同聚类中心学习的角度相互迁移一致性知识。以二部图为桥梁,B可将一致性知识迁移给A(v),从而促使当前视图更好地学习A(v)。得益于协同聚类,A(v)可从多视图数据中提取重要特征。具有群稀疏约束的A(v)可提升处理每个视图的带噪和高维特征的能力,同时提高被提取特征的多样性和完整性。在A(v)提取的多样性信息的基础上,B可通过二部图有选择性地提取多视图一致性知识,从而进一步细化潜在的聚类中心。此外,从A(v)和B迁移知识给E(v),有利于优化E(v)。同时,E(v)借助其特异性,有效提升多视图一致性。
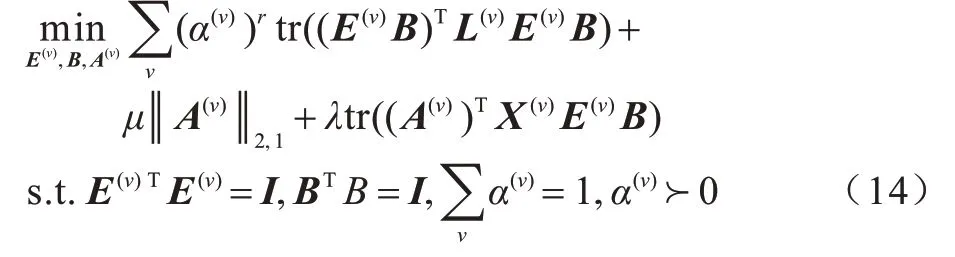
其中:λ为每个视图的谱聚类与协同聚类目标之间的权衡;
μ为稀疏因子。当λ和μ设置为0 时,该模型将退化为具有共同聚类中心的多视图谱聚类。现有的多视图聚类算法[5-7]通过学习一致性嵌入或者一致性图来挖掘多视图一致性。其不足之处在于:一是多视图一致性信息挖掘不充分,MVGL 算法[8]和MCGC 算法[9]由于没有去除冗余信息或考虑噪声矩阵,将对学习到的一致性图造成影响;
二是无法有效地平衡不同视图的质量差异。谱聚类的性能在很大程度上取决于相似矩阵的质量。Co-Reg 算法[23]完全忽略了不同视图相似矩阵之间的质量差异,AASC 算法[24]为每个视图分配了一个特定的权重,但这并不能很好地解决不同相似矩阵之间的质量差异。由于谱嵌入具有严格的一致性约束,AASC 算法很有可能学习到较差的谱嵌入。本文提出的OMTSC 算法旨在解决上述问题。
在多视图聚类任务中,正交基矩阵B迭代迁移一致性知识,聚类编码矩阵E(v)对单个视图聚类任务进行编码。一方面,B可捕获并储存多视图一致性信息,形成潜在聚类中心;
另一方面,加权聚类编码矩阵可更好地平衡不同视图的质量差异。特征嵌入A(v)和B在二部图上相互迁移知识,从而相互促进彼此的学习和优化。
2.2 模型优化
本节将主要探讨对OMTSC 算法模型的优化。显而易见,直接解决问题式(14)是一项具有挑战性的工作,由于它是非凸的,因此本文采用一种交替方向策略来优化多变量问题。首先固定B、A(v)和α(v)更新E(v),然后固定E(v)、A(v)和α(v)更新B,继而固定E(v)、B和α(v)更新A(v),最后固定E(v)、B和A(v)更新α(v)。重复以上步骤直至目标模型收敛。
下面简单介绍更新的过程:
首先明确更新E(v)和B的重点,由于对E(v)和B施加正交约束,因此E(v)和B实际上是位于Stiefel流形上,这个问题可以通过对流形的反复更新来解决,如果E(v)和B不在流形上,则通过更新其在流形上的投影来求解。在迭代过程中,Stiefel 流形由以下命题定义:
命题1假设一个秩为p的矩阵Z,Z在Stiefel 流形上的投影可以定义为:

引入一个变量S来分离上述问题,即:
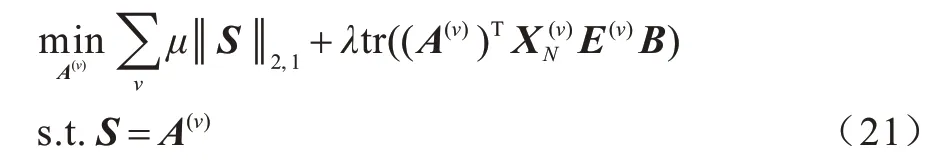
针对上述问题,本文采用ADMM 算法,其增广拉格朗日形式如下:
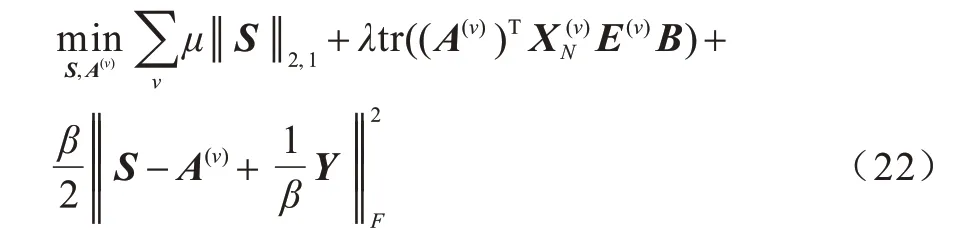
其中:Y是拉格朗日乘数。
然后对于下面问题:
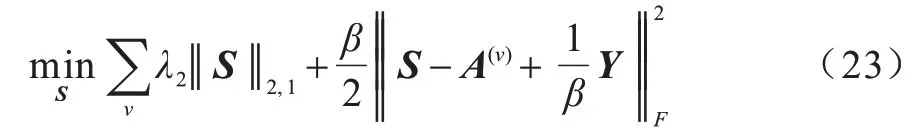
有封闭(closed-form)解,即:

算法1基于正交基的多视图迁移谱聚类


本节选用3 个数据集进行实验,并同时与9 种聚类算法进行比较,以此评估OMTSC 算法的聚类性能。最后分析OMTSC 算法的时间复杂度、收敛性和参数灵敏性。
3.1 数据集
本文选用3 个真实数据集来评估多视图数据聚类的性能。实验数据集包括人脸、图像和文本数据。数据集详细信息如表1 所示。
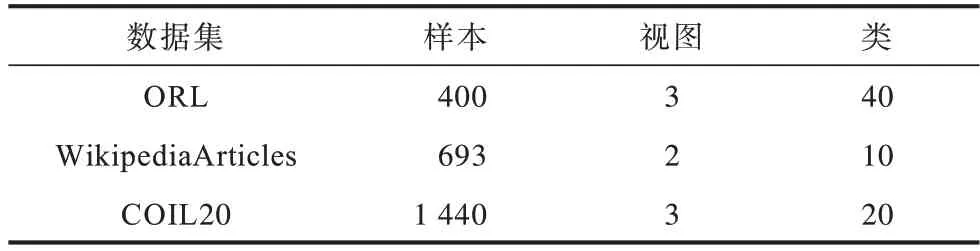
表1 数据集信息Table 1 Introduction to datasets
ORL[27]是人脸识别领域流行的人脸数据库,共有400 个样本,分为40 个类,可由3 个视图描述,分别是强度特征、LBP 特征和Gabor 特征。
WikipediaArticles 可分为30 个类,由于其中一些类很少,因此选取其中10 个最受欢迎的类,选取的数据集共有693 个样本。
COIL20[28]是一个图像数据集,共有1440幅图像,可分为20类,对于每幅图像提取3 个不同的特征向量,包括强度特征、LBP 特征和Gabor 特征。
3.2 对比算法
本文选用1 种单视图聚类算法和8 种多视图聚类算法,与OMTSC 算法进行比较。下文简要介绍对比算法:
1)SC-Best[15]。SC-Best 算法对每个视图中的特征进行标准的谱聚类,并由实验者手动选择最佳的聚类性能作为最终的聚类结果。
2)CoReg SPC[23]。该算法通过对聚类假设进行共正则化,使不同的视图保持一致。
3)AASC[24]。该算法将相似矩阵聚集在一起进行谱聚类。
4)RMSC[29]。该算法为多视图聚类恢复了一个共享的低秩转移概率矩阵。
5)MVGL[8]。该算法从不同的单视图中学习全局图。由于秩约束,因此聚类指标直接由全局图获得。
6)MVGC[9]。该算法利用拉普拉斯矩阵上的秩约束学习一致性图,并利用拉普拉斯矩阵直接获取聚类标签。
7)AWP[5]。该算法利用PA技术从谱嵌入中恢复一致性聚类指标矩阵。
8)WMSC[7]。该算法利用不同视图的归一化拉普拉斯矩阵的特征向量张成子空间之间的最大标准角,它可衡量不同视图聚类结果之间的差异性。因此,最小化标准角可以为所有视图带来更好的聚类一致性。
9)NESE[6]。该算法在统一框架中同时学习非负嵌入和谱嵌入,其中非负嵌入直接揭示了一致的聚类结果,从而提升聚类性能。
本文对每种算法分别进行了10 次实验,通过比较各评估指标的均值和标准差对比聚类性能。所有算法的聚类结果由3 个评估指标测量:即聚类精度(Accuracy,ACC)、归一化互信息(Normalized Mutual Information,NMI)、调整兰特指数(Adjusted Rand Index,ARI)。对于每个评估指标,指标值越大,结果越好。
3.3 实验结果与分析
3 个数据集的聚类结果如表2~表4 所示,其中,粗体字体是最优结果,下划线字体是次优结果,表中数值为均值±标准差。SC-Best 是SC 在单一视图下得到的最佳结果。
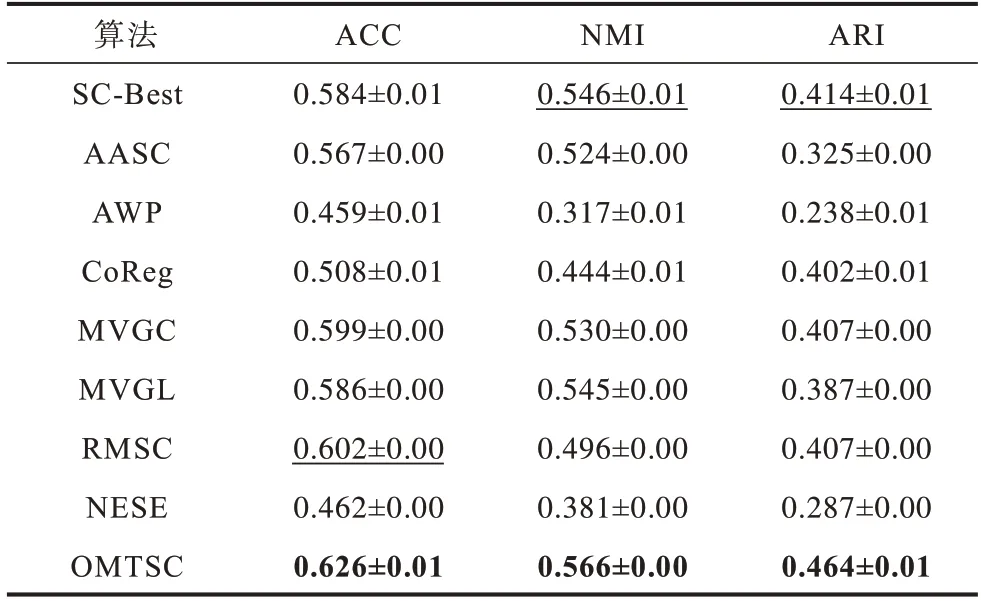
表2 不同算法在WikipediaArticles 数据集上的聚类结果Table 2 Clustering results of different algorithms in WikipediaArticles dataset
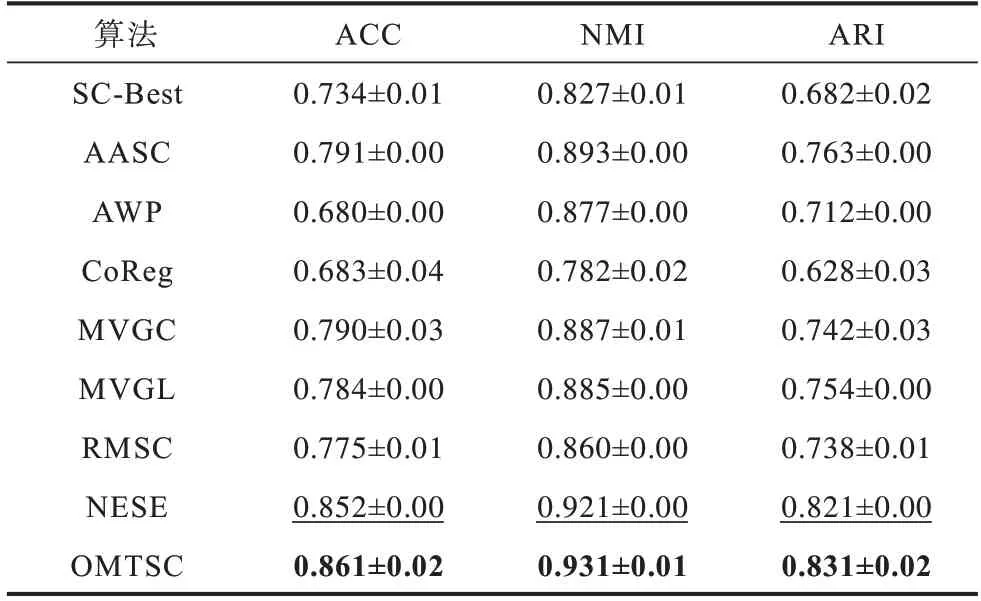
表3 不同算法在COIL20 数据集上的聚类结果Table 3 Clustering results of different algorithms in COIL20 dataset
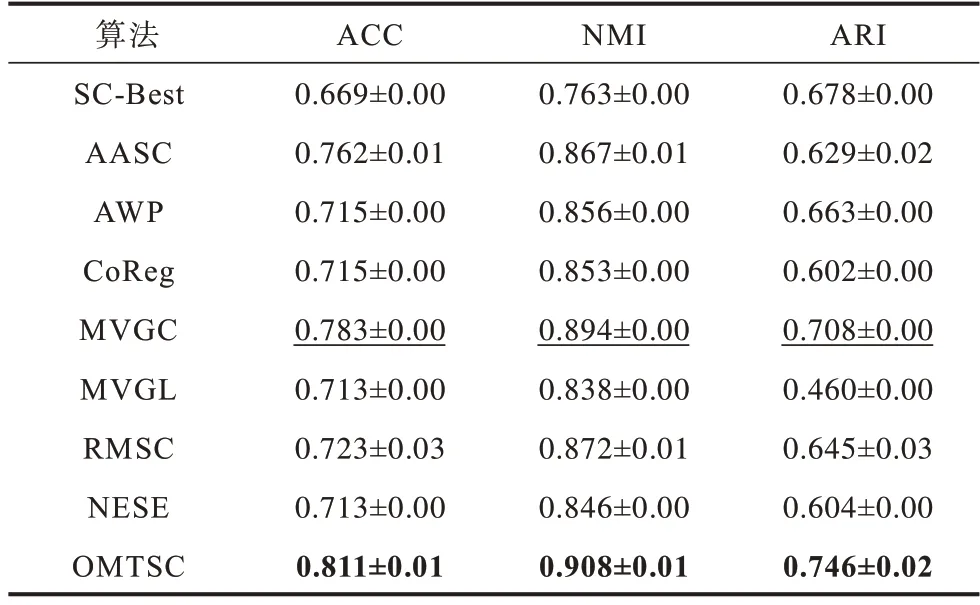
表4 不同算法在ORL 数据集上的聚类结果Table 4 Clustering results of different algorithms in ORL dataset
由表2~表4 可以得出以下结论:
1)在以上3 个数据集中,OMTSC 算法的聚类性能均优于其他算法。特别是在与WikipediaArticles、ORL 数据集上的次优结果相比,OMTSC 算法在ARI指标上的提升超过了近5%。
2)值得注意的是大多数对比算法在不同的数据集上的性能并不稳定。比如NESE 算法在COIL20数据集上取得次优结果,然而在另外两个数据集上的性能并不理想,而OMTSC 算法在不同数据集上保持着最优结果。这是因为NESE 算法是直接学习一致性嵌入,而OMTSC 算法将一致性嵌入分解为公共正交基矩阵和聚类编码矩阵,考虑多视图的一致性和不同视图的特异性,并在模型优化过程中促进两者的相互学习。同时,利用每个视图特征嵌入的多样性来捕获多视图潜在的一致性。
3)与SC-Best 算法和CoReg 算法相比,OMTSC算法可以充分挖掘多视图一致性,捕获潜在聚类中心,并有效消除视图中的噪声和不重要信息,从而提升其聚类性能。其中,SC-Best 算法需要对每个视图分别进行聚类,然后手动选择最佳性能视图,故不适用于实际应用。而CoReg 算法完全忽略了视图相似矩阵之间的质量差异,对学习到的一致的特征向量集有很大影响。OMTSC 算法考虑了不同视图的显著差异,它通过学习加权聚类编码矩阵,可以很好地平衡不同视图相似矩阵之间的质量差异。
4)ORL和COIL20数据集都有3个视图,其中视图的特征数目大多超过3 000 个。由于ORL 和COIL20 数据集的高维性,其中存在一些噪声和冗余信息。OMTSC 算法基于群稀疏约束的特征嵌入,可有效消除视图中的噪声,降低视图中高维和噪声特征对聚类性能的影响。可以看出,与ORL数据集上的MVGL 算法相比,OMTSC 算法在ACC上的提升超过了近10%;
与COIL20 数据集上的MCGC 算法相比,OMTSC 算法在AR 上的提升超过了近10%。这可能是因为MVGL 算法和MCGC算法没有去除冗余信息或噪声矩阵。
综上所述,本文提出的OMTSC 算法在聚类性能及稳定性上,均优于其他先进的多(单)视图聚类算法。
3.4 时间复杂度分析
不同算法的时间复杂度如表5 所示。由算法1可知,OMTSC 算法可分为2 个子问题。对于第1 个问题,涉及计算一个正交基矩阵B和多个聚类编码矩阵E(v)的投影,其计算包括矩阵乘积和加法,时间复杂度为O(n2k)。为了寻求投影,需要对E(v)和B进行奇异值分解。已知对于m×n矩阵,奇异值分解的时间复杂度为O(min{mn2,m2n})。因此,计算正交基矩阵B和聚类编码矩阵E(v)及投影的时间复杂度为O((t1+t2)(n2k))。其中t1和t2分别是E(v)和B单次优化过程的更新迭代次数。对于第2 个问题,OMTSC 算法计算新的特征嵌入A(v)的时间复杂度为O(n2k),新的变量S的时间复杂度为O(max(n2D,n3)k),Y的时间复杂度可忽略不计。因此,OMTSC 算法优化迭代部分的总时间复杂度为O(t3((t1+t2)n2k+max(n2D,n3)k)),其中t3是优化过程的总迭代次数。

表5 不同算法的时间复杂度Table 5 Time complexity of different algorithms
3.5 参数灵敏性
在OMTSC 算法中存在有3 个参数:λ为每个视图的谱聚类与协同聚类目标之间的权衡;
μ为稀疏因子;
r是一个标量,用于控制权重在不同视图上的分布。根据ORL 和WikipediaArticles 数据集的实验结果,分析以上参数对聚类评估指标ACC 的敏感性,其结果如图1 所示。
1)当固定r=2 时,将参数λ和μ设置为[0.000 1,10 000],结果如图1(a)、图1(b)所示。可以看出,在ORL 和WikipediaArticles 数据集中,当λ=[0.000 1,1]和μ=[0.000 1,10 000]时,算法能取得最优性能。由此可知,参数λ对OMTSC 算法的性能较敏感,参数μ对OMTSC 算法的性能不敏感。
2)在ORL 数据集上,固定参数λ=0.1和μ=0.001;
在WikipediaArticles 数据集上,固定参数λ=1和μ=1。同时,将参数r设置为[2,10]。结果如图1(c)、图1(d)所示。由此可知,在这两个数据集上,当r=2 时算法能取得最优性能。
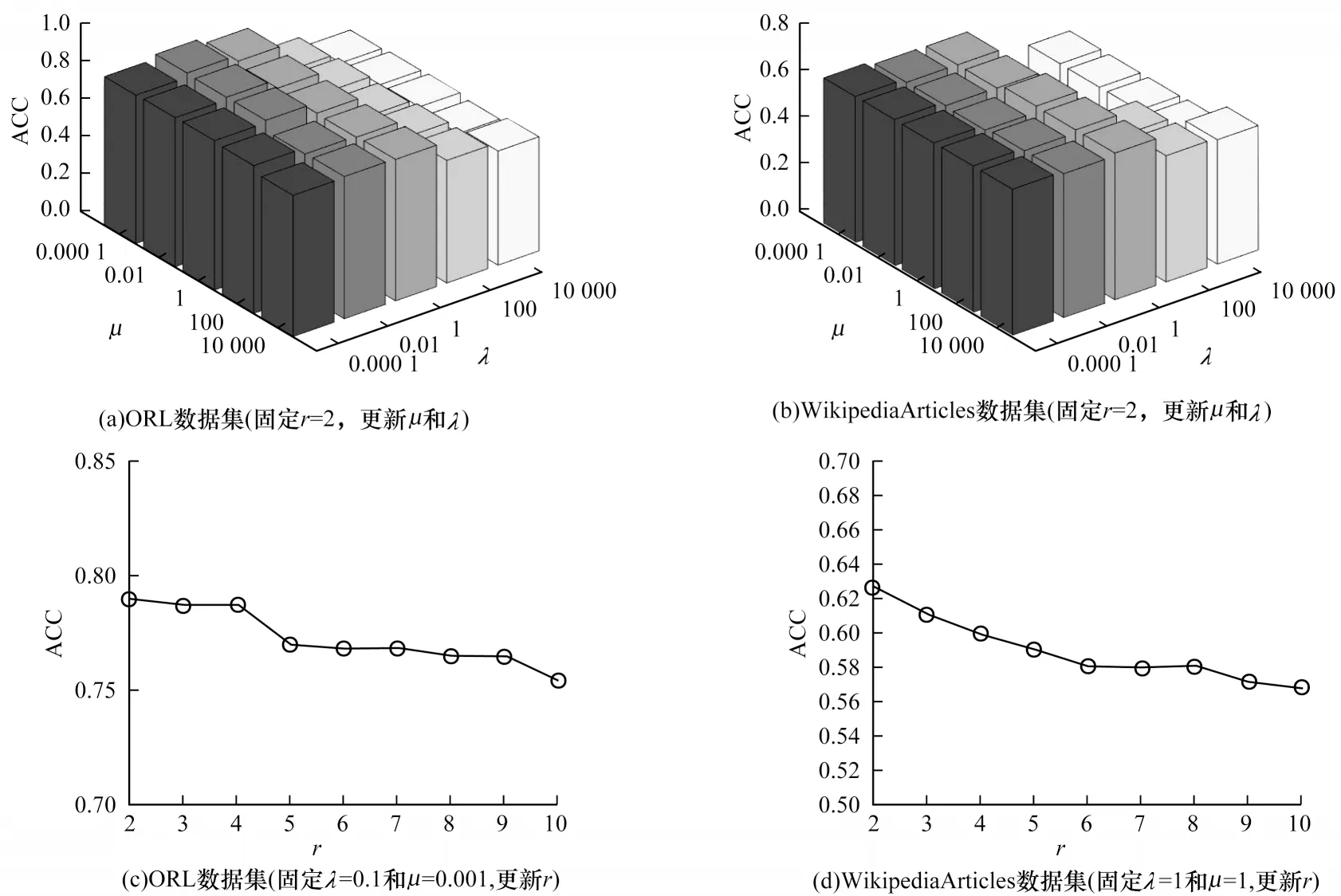
图1 不同参数下OMTSC 算法在ORL 和WikipediaArticles 数据集上的聚类性能Fig.1 Clustering performance of OMTSC algorithm on ORL and WikipediaArticles datasets with different parameters
3.6 收敛性分析
本节采用ORL 和WikipediaArticles 数据集来评估OMTSC 算法的收敛性。当更新E(v)和B时,对应的更新问题分别是E(v)和B的连续函数,故只要步长t1和t2足够小,其值便可单调递减。一般来说,步长t1和t2越小,所需的迭代次数就越大。本文设定t1=t2=1。根据式(14),ADMM 算法[30-31]给出详细的解释,并说明了如何保证该算法的收敛性。
本文提出了一种基于正交基的多视图迁移谱聚类(OMTSC)算法。将每个视图的聚类分配矩阵分解为正交基矩阵和一个聚类编码矩阵,正交基矩阵通过捕获并储存多视图一致性,获取多视图数据的潜在聚类中心。同时,基于加权聚类编码矩阵,OMTSC 可以更好地平衡不同视图之间的质量差异。通过引入协同聚类控制和实现知识迁移,在二部图上同时学习优化特征嵌入和聚类分配矩阵。在此基础上,利用特征嵌入的多样性最大化多视图一致性,学习最优的潜在聚类中心,进而提升多视图聚类性能。此外,本文设计一种交替迭代优化算法对目标函数进行优化,在3 种真实基准数据集上的实验结果验证了该算法的有效性。下一步将考虑构造自适应图,以更好地发现数据的内在关系,提升聚类性能。
猜你喜欢 集上视图一致性 商用车CCC认证一致性控制计划应用汽车实用技术(2022年9期)2022-05-20关于短文本匹配的泛化性和迁移性的研究分析计算机研究与发展(2022年1期)2022-01-19注重教、学、评一致性 提高一轮复习效率教学考试(高考物理)(2021年5期)2021-11-08对历史课堂教、学、评一体化(一致性)的几点探讨历史教学问题(2021年4期)2021-11-05基于互信息的多级特征选择算法计算机应用(2020年12期)2020-12-31视图非公有制企业党建(2017年10期)2017-11-03Y—20重型运输机多视图现代兵器(2017年4期)2017-06-02SA2型76毫米车载高炮多视图现代兵器(2017年4期)2017-06-02Django 框架中通用类视图的用法电脑知识与技术(2016年13期)2016-06-29基于事件触发的多智能体输入饱和一致性控制燕山大学学报(2015年4期)2015-12-25- 范文大全
- 说说大全
- 学习资料
- 语录
- 生肖
- 解梦
- 十二星座
-
主题党日活动交流发言8篇
主题党日活动交流发言8篇主题党日活动交流发言篇13月13日,东城区党史学习教育动员大会召开。市委
【活动总结】 日期:2022-12-23
-
2022年4月主题党日活动记录范文15篇
2022年4月主题党日活动记录范文15篇2022年4月主题党日活动记录范文篇1一个崇尚阅读的民族,必然精神饱满、意气风发、活力四射。习近平总书记强调:“学习
【活动总结】 日期:2022-08-01
-
家乡赋|最美的家乡赋
家乡赋 孙传志 今安康市,白河双丰镇,吾之家乡也。三环沃土,山水环抱。其北依山,山系五岭,山
【调研报告】 日期:2020-04-01
-
【人教版1-6年级数学上册知识点精编】1-6年级数学人教版教材
人教版二年级数学上册知识点汇总第一单元长度单位一、米和厘米1、测量物体的长度时,要用统一的标准去测量
【调研报告】 日期:2020-11-08
-
党支部1-12月全年主题党日活动计划表
2022年党支部主题党日活动计划表序号活动时间活动方式活动内容12022年1月专题学习研讨集中观看2022年新年贺词,积极开展学习研讨交流。组织生活会组织党员认真对照党章...
【活动总结】 日期:2022-10-14
-
2022年2月份主题党日活动记录5篇
2022年2月份主题党日活动记录5篇2022年2月份主题党日活动记录篇1尊敬的党组织:在今年的开学初,本人积极参加教研室组织的教研活动,在学校教研员的指
【活动总结】 日期:2022-08-12
-
少先队的光荣历史故事 队前教育-光辉历程
2017-2018学年队前教育1光辉历程一、劳动童子团1924——1927二、三十年代年的中国是一个
【法律文书】 日期:2020-06-23
-
2023年平安校园建设方案13篇
平安校园建设方案“平安校园”创建工作,我们幼儿园全体教职员工一直把它当作头等大事来抓。领导高度重视,以“平安校园”创建活动为抓手,建立和规范校园安全工作机制
【规章制度】 日期:2023-11-02
-
医院最佳主题党日活动11篇
医院最佳主题党日活动11篇医院最佳主题党日活动篇1 医院最佳主题党日活动篇2为隆重纪念中国共产党成立100周年,进一步巩固党的群众路线教育实践活动成果,切实
【活动总结】 日期:2022-10-29
-
主题党日活动记录202210篇
主题党日活动记录202210篇主题党日活动记录2022篇12021年是中国共产党成立100周年,为广泛开展爱国主义宣传教育,铭记党的历史,讴歌党的光辉历程,
【活动总结】 日期:2022-08-02
-
一年级新学期目标简短_一年级学生新学期打算
新学期到了,我是一年级下册的小学生了。 上课的时候,我要认真学习,不做小动作,认真听讲。我要认真学习,天天向上,努力学习,耳朵要听老师讲课,眼睛要瞪得大大的看老...
【简历资料】 日期:2019-10-26
-
《国行公祭,为佑世界和平》课文原文阅读_国行公祭为佑世界和平每段段意
国行公祭,为佑世界和平钟声“国行公祭,法立典章。铸兹宝鼎,祀我国殇。”侵华日军南京大屠杀遇难同胞纪念
【简历资料】 日期:2020-11-28
-
[信访复查复核制度作用探讨]信访复查复核有用吗
作为我国特有的一项制度,信访制度的出现并长期存在不是偶然的,虽然一些法学专家认为信访制度具有“人治”
【职场指南】 日期:2020-02-16
-
[党员干部2019年主题教育个人问题检视清单及整改措施2篇] 党员干部
2019年主题教育问题检视清单及整改措施根据主题教育领导小组办公室《关于认真做好主题教育检视问题整改
【求职简历】 日期:2019-11-08
-
网络维护工作内容_(精华)国家开放大学电大专科《网络系统管理与维护》形考任务1答案
国家开放大学电大专科《网络系统管理与维护》形考任务1答案形考任务1理解上网行为管理软件的功能【实训目
【职场指南】 日期:2020-07-17
-
民族团结的素材资料13篇
民族团结的素材资料13篇民族团结的素材资料篇1研究进一步推进新疆社会稳定和长治久安工作。会议指出,要全面贯彻执行党的民族政策,把民族团结作为各族人民的生命线
【简历资料】 日期:2022-08-16
-
红旗颂朗诵稿原文【《红旗颂》朗诵词】
《红旗颂》朗诵词 女:晴空万里,红旗飘扬, 六十载风云,我们昂首阔步。 男:六十个春秋,
【职场指南】 日期:2020-02-16
-
党委会与局长办公会的区别_局长办公会制度
为进一步加强xxx局工作的规范化、制度化建设,提高行政效能,规范议事程序,特制定本制度。一、会议形式1、局长办公会议由局长、副局长参加。由局长召集和主持。根据工作需要...
【求职简历】 日期:2019-07-30
-
如何凝心聚力谋发展【坚定信心谋发展凝心聚力促跨越】
当前,清河正处于在苏北实现赶超跨越基础上全面腾飞的战略机遇期,处于在全市率先实现全面小康基础上率先实
【简历资料】 日期:2020-03-17
-
《铁拳砸碎“黑警伞”》警示教育片观后感
影片深刻剖析了广西北海市公安局海西派出所原所长张枭杰蜕变堕落的轨迹。观看警示教育片后,做为一名党员教
【简历资料】 日期:2020-08-17
-
好书读后感—《西游记》:
《西游记》读了《西游记》我深有感触,文中曲折的情节和唐僧师徒的离奇经历给我留下了深刻的印象。本书作者
【口号大全】 日期:2021-05-17
-
区审计局局长述职述廉报告
2022年,在区委、区政府的坚强领导下,我团结带领全体审计干部,深入学习贯彻党的二十大精神和习近平总书记来陕考察重要讲话重要指示精神,紧扣“疫情要防住、经济要稳住、发...
【其他范文】 日期:2023-09-07
-
党史学习建党百年散文3篇
党史学习建党百年散文3篇党史学习建党百年散文篇1从党史中探寻新征程新任务“解锁密码”2月18
【其他范文】 日期:2022-12-21
-
朋友是一首歌【优秀范文】
当前位置:>>>>2021-12-22音乐,有人将它比作花朵,因为它铺满在人生的道路上,散发出不绝的芬芳,把生活装饰得更加美好!世间万籁,其实都是音乐,只看你有没有欣赏它们的耳...
【其他范文】 日期:2022-12-01
-
在学习十六大精神发展合作经济培训会上的总结讲话
同志们: 在市委、市政府的高度重视下,为期两天的学习十六大精神、发展合作经济培训会,顺利完成了会议的各项议程。从收集的情况看,学员反映良好,达到了预期的目的,取...
【口号大全】 日期:2019-07-17
-
庆祝中国共青团成立100周年大会上重要讲话.(精选文档)
讲话,是指说话;发言;谈话,或者指演说和普及性的著作体裁,以下是为大家整理的关于庆祝中国共青团成立100周年大会上的重要讲话 3篇,供大家参考选择。庆祝中国共青团成立10...
【其他范文】 日期:2023-01-02
-
柴胡桂枝汤联合戊酸雌二醇片治疗更年期综合征对患者中医症状积分、激素的影响
凌桂梅彭子圆唐柳英黄淑妙1 广西壮族自治区百色市人民医院中医科,广西百色533000;2 广西壮族自
【其他范文】 日期:2023-04-08
-
【农民运动会开幕式主持词】 农村运动会开场白
尊敬的各位领导、各位来宾、全体运动员、裁判员: 大家好! 百年桔乡掀起欢乐的绿浪,万亩桔林披上节日的盛装。由镇人民政府、区体育局、区农协主办,重庆天建有限公...
【节日庆典】 日期:2019-07-14
-
【镇重点行业领域突出问题专项整治工作实施方案】五小专项治理方案
XX镇重点行业领域突出问题专项整治工作实施方案 根据县扫黑办安排,XX镇结合镇情实际,围绕“10+N
【节日庆典】 日期:2020-09-06
-
校园安全培训个人心得体会【校园安全教育培训心得5篇】
校园安全教育培训心得5篇【篇一】通过这几天的培训学习,我学到了很多的安全知识和预防措施。是的,“生命
【节日庆典】 日期:2020-05-19
-
理论中心组学习总体国家安全观发言材料9篇
理论中心组学习总体国家安全观发言材料9篇理论中心组学习总体国家安全观发言材料篇1(八)深入学习贯彻中央以及省的重要会议和文件精神深入学习贯彻年度内中央以
【发言稿】 日期:2022-08-04
-
军转座谈会交流发言4篇
军转座谈会交流发言4篇军转座谈会交流发言篇1大家好,我叫贺丽,2015届选调生,来自康定市委组织部,现在省委编办跟班学习。今天,非常荣幸向大家汇报我的学习收
【发言稿】 日期:2022-10-27
-
12岁生日小寿星发言4篇
12岁生日小寿星发言4篇12岁生日小寿星发言篇1各位来宾、各位朋友:大家好!今天,我们欢聚在这里,共同庆祝**十二周岁生日。首先,我代表**的父母以
【发言稿】 日期:2022-07-31
-
党内警告处分表态发言14篇
党内警告处分表态发言14篇党内警告处分表态发言篇1尊敬的各位领导、同事们:大家上午好!刚才会上宣布了党委关于我任职的决定,我首先衷心感谢党委的信任和
【发言稿】 日期:2022-09-13
-
党内警告处分党员讨论发言3篇
党内警告处分党员讨论发言3篇党内警告处分党员讨论发言篇1大家好!作为新时期的一名大学生,认真学习、深刻领会、全面贯彻省党代会精神,是当前和今后一个时期重
【发言稿】 日期:2022-08-07
-
廉政大会总结发言稿7篇
廉政大会总结发言稿7篇廉政大会总结发言稿篇1各位领导,同志们:根据会议安排,我就党风廉政建设工作做表态发言,不妥之处,请批评指正。一、提高认识,切实
【发言稿】 日期:2022-10-30
-
【企业疫情风险控制方案】 2020企业复工疫情方案
企业疫情风险控制方案2020新冠病毒肺炎疫情防控工作总结汇报3篇 关于新型冠状病毒感染的肺炎疫
【演讲稿】 日期:2020-02-27
-
被约谈的表态发言8篇
被约谈的表态发言8篇被约谈的表态发言篇1各位领导、各位党员大家好:这天我能站在鲜红的党旗下,
【发言稿】 日期:2022-12-24
-
破冰提能大讨论个人发言4篇
破冰提能大讨论个人发言4篇破冰提能大讨论个人发言篇1党史学习教育开展以来,我坚持读原著、学原文、悟原理。今天,根据会议安排,现在我就“学史明理”主题谈几点个
【发言稿】 日期:2022-10-09
-
巡察整改专题民主生活会总结发言8篇
巡察整改专题民主生活会总结发言8篇巡察整改专题民主生活会总结发言篇1按照区委统一部署和纪监委、巡察办关于召开党史学习教育专题组织生活会的工作安排,近期我紧贴
【发言稿】 日期:2022-10-12
-
2023年中国行政区划调整方案(设想优秀3篇
中国行政区划调整方案(设想优秀民政部第二次行政区划研讨会会议内容一、缩省的意义与原则1.意义1)利于减少中间层次中国行政区划层级之多为世界之最,既使管理成本
【周公解梦】 日期:2024-02-20
-
学习周永开先进事迹心得体会3篇
学习周永开先进事迹心得体会【一】通过学习周永开老先生先进事迹后,结合自己工作思考,感慨万千。同样作为
【格言】 日期:2021-04-10
-
XX老干局推进党建与业务深度融合发展工作情况调研报告:党建调研报告
XX老干局推进党建与业务深度融合 发展工作情况的调研报告 党建工作与业务工作融合发展始终是一个充满生
【成语大全】 日期:2020-08-28
-
中国共产党第三代中央领导集体的卓越贡献
中国共产党第三代中央领导集体的卓越贡献 --------------继往开来铸就辉煌 【摘要】改
【成语大全】 日期:2020-03-20
-
信息技术2.0能力点 [全国中小学教师信息技术应用能力提升工程试题题库及参考答案「精编」]
全国中小学教师信息技术应用能力提升工程试题题库及答案(复习资料)一、判断题题库(A为正确,B为错误)
【格言】 日期:2020-11-17
-
最满意的三项工作200字【最新党办公务员副主任提拔考察个人三年思想工作总结报告】
党办公务员个人三年工作总结近三年来,本人在组织、领导的关心指导和同事们的团结协作下,尽快完成主角的转
【格言】 日期:2021-02-26
-
党建工作运行机制内容有哪些_构建基层党建工作运行机制探讨
党的基层组织是党在社会基层组织中的战斗堡垒,是党的全部工作和战斗力的基础。加强和改进县级以下各类党的
【经典阅读】 日期:2020-01-22
-
集合推理_七,推理与集合
七推理与集合1 期中考试数学成绩出来了,三个好朋友分别考了88分,92分,95分。他们分别考了多少分
【名人名言】 日期:2020-12-18
-
电大现代教育原理_最新国家开放大学电大《现代教育原理》形考任务2试题及答案
最新国家开放大学电大《现代教育原理》形考任务2试题及答案形考任务二一、多项选择题(共17道试题,共3
【成语大全】 日期:2020-07-20
-
2023年和儿媳妇在一起幸福的句子3篇
和儿媳妇在一起幸福的句子1、假如人生不曾相遇,我还是那个我,偶尔做做梦,然后,开始日复一日的奔波,淹没在这喧嚣的城市里。我不会了解,这个世界还有这样的一个你
【格言】 日期:2023-11-10
-
关于三农工作重要论述心得体会3篇
关于三农工作重要论述心得体会3篇关于三农工作重要论述心得体会篇1习近平总书记指出:“建设现代化国家离不开农业农村现代化,要继续巩固脱贫攻坚成果,扎实推进乡村
【学习心得体会】 日期:2022-10-29
-
【福生庄隧道坍塌处理方案】 福生庄隧道在哪里
(呼和浩特铁路局大包电气化改造工程指挥部,内蒙古呼和浩特010050)摘要:文章介绍了福生庄隧道
【学习心得体会】 日期:2020-03-05
-
五个一百工程阅读心得体会13篇
五个一百工程阅读心得体会13篇五个一百工程阅读心得体会篇1凡益之道,与时偕行。在全国网络安全和信
【学习心得体会】 日期:2022-12-07
-
城管系统警示教育心得体会9篇
城管系统警示教育心得体会9篇城管系统警示教育心得体会篇1各党支部要召开多种形式的庆七一座谈会,组织广大党员进行座谈,回顾党的光辉历程,畅谈党的丰功伟绩,
【学习心得体会】 日期:2022-10-09
-
发展对象培训主要内容10篇
发展对象培训主要内容10篇发展对象培训主要内容篇1怀着无比激动的心情,我有幸参加了__新区区委党校20__年第四期(区级机关)党员发展对象培训班。这次的学习
【培训心得体会】 日期:2022-09-24
-
扶眉战役纪念馆心得体会11篇
扶眉战役纪念馆心得体会11篇扶眉战役纪念馆心得体会篇1有那么一段历史,低诉着血和泪的故事,慢慢地,随岁月老去;有那么一群人,放弃了闲逸的人生,辗转奔波中
【学习心得体会】 日期:2022-08-03
-
2022年全国检察长会议心得7篇
2022年全国检察长会议心得7篇2022年全国检察长会议心得篇1眼睛是心灵上的窗户,我们通过眼睛才能看到世间万物,才能看到眼前这美好的一切。拥有一双明亮的眼
【学习心得体会】 日期:2022-10-31
-
全面从严治党的心得体会800字7篇
全面从严治党的心得体会800字7篇全面从严治党的心得体会800字篇1中国特色社会主义是我们党领导
【学习心得体会】 日期:2022-12-14
-
矫正心得体会6篇
矫正心得体会6篇矫正心得体会篇1今天,是自己出监后第一次参加阳光中途之家组织的社区矫正方面的教育
【学习心得体会】 日期:2022-12-24
-
2月教师党员个人思想汇报5篇
2月教师党员个人思想汇报敬爱的党组织:最近这一个月的时间对于我来说是极不平凡的,在这段时间里我认真学习了文化部网上党校的相关内容,经过长达40小时的
【教师心得体会】 日期:2023-10-15
-
 2024年主题教育民主生活会批评与自我批评意见(38条)(范文推荐)
2024年主题教育民主生活会批评与自我批评意见(38条)(范文推荐)
2023年主题教育民主生活会六个方面个人检视、相互批评意见:1 理论学习系统性不强。学习习近平新时代中国特色社会主义思想不深不透,泛泛而学的时候多,深学细照的时候少,特...
【邓小平理论】 日期:2024-03-19
-
 2024年交流发言:强化思想理论武装,增强奋进力量(完整)
2024年交流发言:强化思想理论武装,增强奋进力量(完整)
习近平总书记指出:“一个民族要走在时代前列,就一刻不能没有理论思维,一刻不能没有思想指引。”党的十八大以来,伴随着新时代中国特色社会主义思想在实践中形成发展的历程...
【三个代表】 日期:2024-03-19
-
2024年度镇年度县乡人大代表述职评议活动总结
xx镇20xx年县乡人大代表述职评议活动总结为响应县级人大常委会关于开展县乡两级人大代表述职评议活动,进一步激发代表履职活力,加强代表与人民群众的联系,提高依法履职水平...
【马克思主义】 日期:2024-03-19
-
 “千万工程”经验学习体会(研讨材料)
“千万工程”经验学习体会(研讨材料)
“千万工程”是总书记在浙江工作时亲自谋划、亲自部署、亲自推动的一项重大决策,也是习近平新时代中国特色社会主义思想在之江大地的生动实践。20年来,“千万工程”先后经历...
【三个代表】 日期:2024-03-19
-
 2024年在市政协机关工作总结会议上讲话
2024年在市政协机关工作总结会议上讲话
同志们:刚才,XX同志对市政协机关20XX年工作进行了很好的总结,很精炼,很到位,可以感受到去年机关工作确实可圈可点。XX同志宣读了表彰决定,机关优秀人员代表、先进集体代...
【邓小平理论】 日期:2024-03-18
-
 在全区防汛防涝动员暨河长制工作推进会上讲话提纲【完整版】
在全区防汛防涝动员暨河长制工作推进会上讲话提纲【完整版】
区长,各位领导,同志们:汛期已经来临,我区城区防涝工作面临强大考验,形势不容乐观。年初,区城区防涝排渍指挥部已经召开专题调度会,修订完善应急预案,建立网格化管理机...
【马克思主义】 日期:2024-03-18
-
 2024年镇作风整治工作实施方案(完整文档)
2024年镇作风整治工作实施方案(完整文档)
XX镇作风整治工作实施方案为深入贯彻落实党的二十大精神及省市区委深化作风建设的最新要求,突出重点推进干部效能提升,坚持不懈推动作风整治工作纵深发展,根据《关于印发《2...
【毛泽东思想】 日期:2024-03-18
-
2024市优化法治化营商环境规范涉企行政执法实施方案【优秀范文】
xx市优化法治化营商环境规范涉企行政执法实施方案为持续优化法治化营商环境,激发市场主体活力和社会创造力,规范行政执法行为,创新行政执法方式,提升行政执法质效,着力解...
【毛泽东思想】 日期:2024-03-18
-
 2024年度关于开展新一轮思想状况摸底排查工作通知(完整)
2024年度关于开展新一轮思想状况摸底排查工作通知(完整)
关于开展新一轮思想状况摸底排查工作的通知为深入贯彻落实关于各地开展干部职工思想状况大摸底大排查情况上的批示要求和改革教育第二次调度会议精神,有针对性做好队伍教育管...
【三个代表】 日期:2024-03-18
-
2024年公路养护中心主任典型事迹材料(完整文档)
“中心的工作就是心中的事业”——公路养护中心主任典型事迹材料**,男,1976年6月出生,1993年参加工作,2000年4月调入**区交通运输局工作,大学本科学历,中共党员,现任**...
【马克思主义】 日期:2024-03-17