小样本条件下的RGB-D显著性物体检测
何静,傅可人,2*
1.四川大学视觉合成图形图像技术国防重点学科实验室,成都 610065;
2.四川大学计算机学院,成都 610065
显著性物体检测(salient object detection, SOD)旨在定位图像或视频中最吸引人注意力的物体,并将其从背景中分离出来。显著性物体检测主要应用于计算机视觉任务中的预处理,如视频/图像分割、视觉追踪、视频/图像压缩等。在早期,显著性物体检测主要基于RGB图像进行检测,从输入的RGB图像中提取有用信息用于物体显著程度的估计。近年来,随着深度传感器的发展和普及,基于RGB-D(RGB-depth)的多模态显著性物体检测受到研究者们广泛的关注。
现有的RGB-D SOD方法按监督方式可以分为全监督和自监督两种。全监督RGB-D SOD(Fu等,2020;
Zhang等,2020)对输入的RGB图像以及相应的深度图通常采用早期融合、中期融合和后期融合的方式将两种不同模态的互补信息进行有效融合。自监督RGB-D SOD(Zhao等,2021)用少量无标记RGB-D数据集进行预训练,使网络捕获丰富的上下文语义信息,从而为下游任务提供有效初始化。
目前大多数RGB-D SOD采用全监督的方式在一个较小的RGB-D SOD训练集上进行训练,然而,此方式的泛化性能局限于较少的训练样本,难以泛化到真实场景。因此,本文提出将RGB-D SOD视为小样本学习问题。受Wang等人(2021)综述的启发,本文应用两类小样本学习方法,第1类为基于模型解空间优化的方法,通过多任务训练以及参数共享的方式将训练样本数量较多的RGB SOD任务学习到的知识迁移至训练样本数量较少的RGB-D SOD任务,从模型角度约束特征解空间;
第2类为基于训练样本扩充的方法,利用单图深度估计算法将额外的RGB图像生成相应的深度图,再将得到的RGB-D图像对用于训练样本扩充。通过对以上两类方法的结果进行对比分析,证明了引入小样本学习来提升RGB-D SOD性能的可行性和有效性。本文的主要贡献如下:
1)提出将RGB-D SOD视为小样本学习问题,根据小样本学习方法的分类,从模型解空间优化角度和训练样本扩充角度研究如何从RGB SOD任务迁移额外的先验知识,以提高小样本条件下的RGB-D SOD的性能和泛化性。与之前方法不同,本文从“训练样本少”的角度出发,利用小样本学习方法进行显著性物体检测的研究工作。
2)针对不同小样本学习方法,研究并实验了不同的显著性检测策略(包括典型的中期融合模型和后期融合模型),并在9个常用基准数据集上进行定量、定性的实验和分析,结果表明将RGB-D SOD视为小样本学习问题具有有效性和可行性。
1.1 RGB-D显著性物体检测
近年来,RGB-D SOD在性能上取得了质的飞跃。传统的RGB-D SOD主要采用提取的手工特征将RGB图像信息与深度图信息进行融合。Niu等人(2012)提出第1个传统的基于RGB-D的显著性物体检测,利用全局视差对比和立体规则进行显著性估计。传统的RGB-D SOD模型,往往通过深度线索探索有用的属性,如边界线索、区域对比度、深度对比度和形状属性等。其中,Peng等人(2014)采用多阶段的RGB-D算法将深度和外观线索结合用于显著性物体的分割。值得一提的是,他们构建了第1个大规模的RGB-D SOD基准数据集,即 NLPR。虽然传统的RGB-D SOD取得了不错的效果,但它们在复杂场景、低对比度和强光照等环境缺乏鲁棒性和泛化性。
Qu等人(2017)首次提出基于卷积神经网络的RGB-D显著性物体检测,利用卷积神经网络有效地学习输入图像的低级特征和深度线索,并通过卷积神经网络整合以获得最终的显著性检测结果,开启了基于深度神经网络的RGB-D SOD新方向。为充分利用RGB图与深度图的互补信息,CTMF方法(Han等,2018)利用卷积神经网络(convolutional neural network, CNN)学习RGB图像和深度图中的高级表示,将模型结构从RGB图像转移到深度图。Zhao等人(2019)提出一种流体金字塔集成模块,通过分层的方式有效融合跨模态信息。MMCI(Chen等,2019)利用多尺度多路的融合方式捕获RGB图像与多层深度线索之间的相关性。UC-Net(Zhang等,2020)提出通过条件变分自编码器对人的注释不确定性进行建模以产生不同的显著性预测,最终通过投票机制预测准确的显著性图。JL-DCF(Fu等,2020)将深度图与RGB图像进行级联输入到共享卷积神经网络进行特征提取,并提出一种密集协作融合策略,有效地融合不同模态学习到的特征。D3Net(Fan等,2021)通过判断深度图是否应该与RGB图像串联作为输入信号,设计网络以减少低质量深度图引入的噪声,并构造了一个新的RGB-D SOD基准数据集(SIP)。
由此可见,基于RGB-D的显著性物体检测在过去几年得到了快速发展,并获得较好的性能。但这些方法往往注重RGB与深度特征的有效融合(李贝 等,2021),如设计早期融合、中期融合、晚期融合和多尺度融合等策略。而本文关注RGB-D SOD的训练样本较少,导致网络泛化能力具有一定局限性的问题。因此提出将RGB-D SOD视为小样本学习问题,研究如何将RGB SOD任务学习到的知识迁移到RGB-D SOD任务,并基于JL-DCF模型(Fu等,2020)和DANet(dual attention network for scene segmentation)模型(Fu等,2019),探讨引入小样本学习方法后,对RGB-D SOD带来的性能提升。
1.2 小样本学习
小样本学习任务旨在解决如何在监督信息有限的样本条件下增强目标任务的学习,通常见于小样本分类问题(徐鹏帮 等,2021),即N-way-K-shot问题。与小样本分类任务不同,本文利用RGB SOD任务与RGB-D SOD任务间的共性,解决RGB-D SOD监督信息有限的问题,增强RGB-D SOD任务的特征学习和泛化性。
目前,鲁棒的机器学习算法模型离不开大量的训练数据,但实际中训练样本的获取往往较难,小样本问题广泛存在于深度学习领域,因此近年来小样本学习方法成为热门方向,研究者们尝试探索小样本学习方法在不同领域的应用。小样本学习在特征识别(Finn等,2017;
Munkhdalai和Yu,2017;
Snell等,2017)和图像分类(Ravi和Larochelle,2017;
Tsai等,2017;
Wang和Hebert,2016)的应用较广,在Ominiglot和miniImageNet两个基准数据集均取得较高的准确率。在视频方向也有较多应用,如视频分类(Zhu和Yang,2018)、动作预测(Gui等,2018)、行人重识别(Wu等,2018)、目标分割(Caelles等,2017)等。尽管小样本学习方法应用于众多领域,但目前尚未有工作将小样本学习方法应用于显著性物体检测。与现有RGB-D SOD文献不同,本文发现并尝试解决RGB-D SOD的小样本问题。
本文在Wang等人(2021)综述的启发下,探索小样本条件下的RGB-D SOD,研究两类不同的小样本学习方法在RGB-D SOD领域的综合性能表现,对基于两类小样本学习方法的RGB-D SOD进行对比分析。首先,从模型解空间优化角度,使RGB-D SOD任务和RGB SOD任务进行多任务学习共享权重参数,利用两个关联任务学习任务之间的共性,从模型角度约束参数,从而实现小样本条件下的RGB-D SOD。从训练样本扩充角度,使用现有的单目深度估计算法生成相应的深度图,即直接利用RGB SOD数据集中的先验知识对数据进行增强,从而扩充小样本条件下的RGB-D SOD有监督数据。
RGB SOD与RGB-D SOD的多任务学习方法需为额外的RGB图像进行监督,因此选择中期融合模型与后期融合模型作为本文框架。原因有:1)早期融合将RGB图像与深度图像在通道维度进行级联输入网络,或者将RGB图像与深度图像的浅层表示合并后输入网络进行显著性预测,在输入阶段将RGB图像与深度图进行级联,因此不能分别对RGB图像和深度图进行监督;
2)中期融合将RGB图像与深度图像分别输入相应的网络,通过双流网络的方式获得特征,再将特征融合后输入深度神经网络解码器进行显著性预测,可为网络添加额外的监督信号;
3)后期融合则利用双流网络分别提取RGB图像特征以及深度图像特征,将提取的特征联合用于最终的显著性预测。因此,由于采用了双流网络结构,中期融合和后期融合均可作为两类小样本学习方法的基本框架。

2.1 基于模型解空间优化
从模型解空间优化角度,小样本学习方法可以通过增加先验知识限制模型假设空间,使经验风险最小化的结果更可靠,并且降低过拟合风险(Wang等,2021)。根据先验知识的利用方法,将基于模型的小样本学习方法分为多任务学习、嵌入学习和生成式模型(Wang等,2021)。采用多任务学习方法,将两个相似任务进行参数共享,从而将RGB SOD任务的知识迁移至RGB-D SOD模型中。
考虑到从模型解空间优化角度进行多任务学习需要加入额外的监督信号,选择中期融合和后期融合模型对小样本RGB-D SOD进行探究。在中期融合模型中,Fu等人(2020)提出的JL-DCF是具有代表性的中期融合模型,同时,JL-DCF对RGB图像和深度图两种模态均有单独的监督;
另外,JL-DCF共享了RGB分支和深度分支的权重,使额外的RGB图像信息更好地增强两种模态的学习。对于后期融合模型,参考Fu等人(2021)将DANet(Fu等,2019)构造为双流后期融合模型DANet†,用于多任务学习,框架图如图1所示。
图1(a)表示基于中期融合的小样本条件下的RGB-D SOD,网络主干部分为JL-DCF模型。JL-DCF(Fu等,2020)通过孪生网络提取RGB图像与深度图像的特征,并提出密集协作融合策略有效地融合不同模态的特征。本文在编码模块对RGB-D SOD任务和RGB SOD任务进行参数共享,为引导网络更好地学习多任务特征,将特征编码器输出的粗略显著图进行监督从而优化编码模块以提高模块的泛化能力。解码器将RGB-D数据编码的各级特征与解码部分的各级特征进行跨模块融合,最后输出精确的显著预测图。其中,RGB-D SOD任务的训练数据远小于RGB SOD任务的训练数据。

图1 将多任务学习用于基于中期融合和后期融合的RGB-D SOD模型(RGB*表示额外的RGB图像)
图1(b)表示基于后期融合的小样本条件下的RGB-D SOD,网络主干部分为DANet模型。DANet(Fu等,2019)为基于RGB的语义分割模型,通过多尺度特征融合捕获上下文信息,同时采用双注意力网络以自适应地将局部特征与其全局依赖性相结合,分别对空间和通道维度的语义相互依赖性进行建模。本文参考Fu等人(2021)将语义分割模型DANet的分类预测头卷积层(1×1,C)(输出通道数C表示语义分割类别数)替换为(1×1,1)的预测卷积层以用于显著性物体检测。由于DANet为基于RGB的单流模型,因此将DANet修改为输入为RGB图像和深度图像的双流后期融合模型,即DANet†。对输入的RGB图像与深度图像进行编解码操作得到单通道激活特征图,再在输入Sigmoid函数前进行相加融合操作得到最终的显著性图。
综上,基于中期融合和后期融合的多任务学习方法的总体损失分别表示为
L1=L(Sr,G)+L(Sd,G)+L(Sr*,G*)+L(Sf,G)
(1)
L2=L(Sr*,G*)+L(Sf,G)
(2)

2.2 基于训练样本扩充

当加入了额外的合成数据,数据集的分布将发生改变,即小部分为原始RGB-D数据,大部分则为合成数据,因此为了减小数据量对网络训练的影响,深度生成时,将合成数据的训练损失按数据比例进行加权,因此深度生成方法的损失函数为
(3)

3.1 数据集与评估指标
为公平比较,在8个RGB-D SOD数据集以及1个RGB SOD数据集上进行实验,并对实验结果进行评价分析。RGB-D SOD数据集包括:NJU2K(1 985个样本)(Ju等,2014)、NLPR(1 000个样本)(Peng等,2014)、STERE(1 000个样本)(Niu等,2012)、RGBD135(135个样本)(Cheng等,2014)、LFSD(100个样本)(Li等,2017)、SIP(929个样本)(Fan等,2021)、DUT-RGBD(800个训练样本+400个测试样本)(Piao等,2019)、ReDWeb-S(2 179个训练样本+1 000个测试样本)(Liu等,2021)。DUTS(10 553个训练样本+5 019个测试样本)(Wang等,2017)为RGB SOD数据集。在本文中,RGB-D训练集由NJU2K的1 500个样本、NLPR的700个样本组成,额外的RGB训练数据由DUTS中10 553个样本组成。其余数据用于测试,值得一提的是,在DUT-RGBD和ReDWeb-S中,采用所有数据进行测试,即测试集分别包含1 200个和3 179个样本。
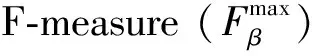
3.2 实验细节
本文方法的实现基于JL-DCF框架和DANet†框架。在基于JL-DCF的多任务学习实验中,将RGB-D数据与DUTS中的RGB数据同时输入编码器进行在线联合训练和优化。相似地,基于DANet†的多任务学习实验对两种不同来源的RGB数据同时进行联合训练和优化。JL-DCF框架和DANet†框架的主干网络均为ResNet-101,其中JL-DCF网络与DANet†网络输入图像的尺寸分别为320×320×3、480×480×3,最终输出图像分辨率分别为320×320像素、480×480像素,两个网络的输入均是将深度图通过简单的灰度映射转换为三通道图。

3.3 实验结果对比与分析
3.3.1 定量结果对比和分析
为直观地说明将RGB-D SOD视为小样本学习问题的有效性和泛化性,训练了6个不同模型验证两种不同的小样本学习方法(即RGB SOD与RGB-D SOD的多任务学习,以及训练样本深度生成)对RGB-D SOD的性能提升。如表1所示,其中W/o FSL表示原始Pytorch版本的模型性能(未采用小样本学习方法),Multi-task表示RGB SOD与RGB-D SOD多任务学习优化的方法,DS-DPT、DS-MD分别表示基于DPT和MegaDepth的深度生成的训练样本扩充。值得一提的是,表1中DUTS为RGB SOD数据集,因此在测试时通过DPT和MegaDepth两种方法生成深度图,分别表示为DUTS(DPT)、DUTS(MD)。

表1 在9个数据集上的定量分析
从表1可得:
1)由JL-DCF与DANet†的结果可得,将RGB-D SOD视为小样本学习问题并引入小样本学习方法可提高模型性能。例如,对于JL-DCF模型,多任务学习方法(multi-task)在SIP和DUT-RGBD数据集性能表现总体最好,Sα的提升分别为2.1%、2.4%;
对于DANet†模型,基于DPT的深度生成方法(DS-DPT)在SIP和DUT-RGBD数据集上,Sα的提升分别为1.8%、3.9%。
2)在JL-DCF结果中,多任务学习方法(multi-task)的性能表现最佳,相比于未引入小样本学习(W/o FSL)的性能总体提升最高,这源于JL-DCF模型通过参数共享的方式将RGB SOD任务的知识迁移至RGB-D SOD任务,此方式更有利于显著性物体检测任务的特征学习。
3)在DANet†结果中,基于DPT的深度生成(DS-DPT)性能总体提升最高,且高于多任务学习(multi-task)。原因在于采用DPT方法合成的高质量深度图进行网络训练,使基于DPT的深度生成方法(DS-DPT)性能提升最高。另一方面,DANet†通过双流网络分别学习RGB图像与深度图像的特征,并以后期融合的方式融合两支路(RGB分支、深度图分支)的特征,在特征学习阶段额外的RGB图像信息仅有利于RGB分支的学习,而深度分支未能利用额外的RGB图像信息,因此多任务学习方法性能表现稍差。
4)分析JL-DCF和DANet†数据中DS-DPT与DS-MD的性能表现,结果显示两类模型中DS-DPT的总体性能均要优于DS-MD,可得出深度生成的质量对结果有一定的影响,即深度生成算法效果越好,引入额外的RGB图像知识所带来的性能提升越大。
5)JL-DCF的整体性能优于DANet†,因此小样本条件下的RGB-D显著性物体检测依赖于模型的选择。与UCNet(Zhang等,2020)、SSRNet(Zhao等,2020)两种现有前沿方法进行对比,引入小样本学习方法后可获得优于SOTA(state-of-the-art)的性能。同时,在DUT-RGBD、ReDWeb-S两个全数据集上的测试结果证明了在RGB-D SOD模型引入小样本学习方法的泛化性。
为直观表现采用小样本学习方法对JL-DCF与DANet†模型的性能提升,对表1中数据进行统计归纳,得出将RGB-D SOD视为小样本学习问题后,多任务学习以及深度生成方法在8个通用数据集的性能提升(仅计算NJU2K、NLPR、STERE、RGBD135、LFSD、SIP、DUT-RGBD、ReDWeb-S数据集上的指标提升平均值),如表2所示,在JL-DCF模型中,多任务学习方法具有突出的性能表现,在DANet†模型中,基于DPT方法的深度生成性能提升较为突出,如前所述,此结果与基础模型的结构相关。另外,JL-DCF模型引入小样本学习方法的性能提升要小于DANet†模型引入小样本学习方法的提升,原因为原始JL-DCF性能表现已较好,而DANet†模型性能稍差,说明小样本学习方法对模型带来的性能提升一定程度上取决于模型自身的基础性能。表2再次证明了将RGB-D SOD视为小样本学习问题的可行性和有效性。

表2 小样本学习方法的平均性能提升
表3展示了将模型用于DUTS数据集的性能提升,DUTS(DPT)、DUTS(MD)分别表示采用DPT方法和MegaDepth方法生成DUTS数据集的深度图用于测试。在JL-DCF模型中,采用DPT方法生成深度图训练的模型在DPT方法生成深度图的测试集上性能表现最佳,采用MegaDepth方法生成深度图训练的模型在MegaDepth方法生成深度图的测试集上性能表现最佳。对于DANet†模型,DPT方法生成深度图训练的模型(即DS-DPT)在DUTS(DPT)与DUTS(MD)数据集上性能表现最佳,原因在于DANet†为后期融合模型,对RGB-D图像对的语义信息的利用较差,因此深度图的质量对此双流网络的影响较大,印证了基于训练样本扩充的小样本学习方法的性能依赖于深度生成算法的性能。另外,由于额外的RGB图像仅有利于RGB分支学习特征,而没有学习生成的深度图信息,因此多任务学习(即multi-task)性能差于深度生成方法。总之,采用不同深度生成方法训练的模型能够在不同的测试集(DUTS(DPT)、DUTS(MD))取得较优的性能提升(Sα最低提升2.9%),证明引入小样本学习方法可提高模型的泛化性。

表3 DUTS数据集上小样本学习方法的性能提升
为验证引入小样本学习对RGB-D SOD在训练样本数量极少时的优越性,本文将RGB-D SOD训练样本数按1/4进行指数式减少(即从2 200依次减少为550、138、35个RGB-D训练样本),而额外的RGB SOD训练样本数量则保持不变,以使RGB SOD数据量远大于RGB-D SOD数据量。本文选择基于JL-DCF的多任务学习方法进行验证。如表4所示,其中Δ1、Δ2、Δ3、Δ4分别表示样本数量为2 200、550、138、35时,多任务学习方法在9个数据集上的平均提升(基准模型W/o FSL也使用减少的样本进行了重新训练)。由表4给出的实验结果可知,当RGB-D SOD训练样本数为2 200和550时,引入小样本学习方法对该任务的性能提升相当,但随着样本数量的指数减少,多任务学习方法的性能提升越发显著。

表4 指数减少RGB-D数据量时多任务学习方法的平均性能提升
3.3.2 定性结果对比和分析
由图2可得,小样本条件下的显著性物体检测准确率更高。同时,对于背景较复杂的图像也可以准确地检测出显著性物体。本文方法在DANet†模型与JL-DCF模型上均能明显提高检测准确率。由此证明了小样本条件下的RGB-D SOD的可行性,表现为所得到的显著性物体更加完整,置信度也更高。

图2 定性比较
3.3.3 参数α的敏感性分析
为分析基于训练样本扩充方法式(3)中权重系数的取值影响,设置α值分别为0、0.21、1、5在JL-DCF模型上进行实验,在NJU2K、NLPR、STERE、RGBD135、LFSD、SIP、DUT-RGBD、ReDWeb-S数据集上的各项平均指标如图3所示。值得一提的是,α=0即表示不采用合成训练数据的原始性能(对应表1中JL-DCF栏的W/o FSL);α=1意味着对所有训练样本同等对待,而α=5表示增加了合成数据的训练权重。从图3可见,当α=0.21时,网络取得的性能最好。随着α取值的增大,即扩大合成数据集对网络前向传播的影响,意味着网络逐渐偏向学习合成的深度信息,因此导致在真实的RGB-D数据上性能有所下降。上述实验表明,在训练样本扩充时控制好合成数据的权重更有益于模型性能的提升,也证明了本文对α取值的有效性。

图3 在8个数据集上对参数α的不同取值(0、0.21、1、5)进行敏感性分析
3.3.4 其他讨论
基于以上对实验结果的定量、定性分析,可证明将RGB-D SOD视为小样本学习问题的可行性和有效性,但这两类小样本学习方法存在各自的优缺点。在适用性方面,多任务学习方法局限于模型的结构,仅可应用于中期融合模型与后期融合模型,如本文第2节所述,早期融合模型无法为网络加入额外的监督信号;
而深度生成方法简单直接,理论上可应用于所有模型。另外,对于训练复杂度,深度生成方法受大量训练数据的影响,训练时间较长;
而多任务学习方法训练时间较短,训练代价较低。此外,基于深度生成方法的小样本RGB-D SOD性能一定程度上依赖于深度生成算法的精度,低质量的深度图易给网络引入噪声,从而影响最终的训练结果。
针对RGB-D SOD训练数据集较小的问题,本文从小样本学习角度探讨RGB-D SOD。鉴于RGB SOD任务与RGB-D SOD任务的相似性以及数据的可用性,利用小样本学习方法将RGB SOD任务的知识迁移到RGB-D SOD任务,从模型解空间优化和训练样本扩充对小样本条件下的RGB-D SOD进行研究。模型解空间优化将RGB SOD与RGB-D SOD进行多任务学习共享参数,通过引入RGB SOD任务的知识,使网络学习更具泛化性的特征。训练样本扩充利用单目深度生成算法生成相应的深度图,以实现RGB-D SOD训练数据集的增广。本文进行了大量实验,从不同角度证明小样本条件下的RGB-D SOD的有效性和可行性。总之,面向小样本条件下的RGB-D SOD的研究是一项重要任务,目前仅从模型解空间优化角度和训练样本扩充角度对小样本条件下的RGB-D SOD方法进行研究,未来将探索并应用更多小样本学习方法以提升RGB-D显著性物体检测,乃至其他显著性检测任务的性能。
猜你喜欢 多任务显著性样本 数字时代的注意困境:媒体多任务的视角*应用心理学(2022年5期)2022-11-05一种结合多尺度特征融合与像素损失加权的显著性目标检测方法黑龙江大学自然科学学报(2022年1期)2022-03-29结合自监督学习的多任务文本语义匹配方法北京大学学报(自然科学版)(2022年1期)2022-02-21视频序列中视觉显著性图像区域自动提取仿真计算机仿真(2021年7期)2021-11-17面向多任务的无人系统通信及控制系统设计与实现现代信息科技(2021年21期)2021-05-07欧盟法院判决明确欧盟商标通过使用获得显著性的地域认定标准中国知识产权(2018年12期)2018-12-29规划·样本领导决策信息(2018年16期)2018-09-27人大专题询问之“方城样本”人大建设(2017年10期)2018-01-23商标显著性的司法判断(一)中国知识产权(2017年5期)2017-05-25随机微分方程的样本Lyapunov二次型估计数学学习与研究(2017年3期)2017-03-09- 范文大全
- 说说大全
- 学习资料
- 语录
- 生肖
- 解梦
- 十二星座
-
主题党日活动交流发言8篇
主题党日活动交流发言8篇主题党日活动交流发言篇13月13日,东城区党史学习教育动员大会召开。市委
【活动总结】 日期:2022-12-23
-
2022年4月主题党日活动记录范文15篇
2022年4月主题党日活动记录范文15篇2022年4月主题党日活动记录范文篇1一个崇尚阅读的民族,必然精神饱满、意气风发、活力四射。习近平总书记强调:“学习
【活动总结】 日期:2022-08-01
-
家乡赋|最美的家乡赋
家乡赋 孙传志 今安康市,白河双丰镇,吾之家乡也。三环沃土,山水环抱。其北依山,山系五岭,山
【调研报告】 日期:2020-04-01
-
少先队的光荣历史故事 队前教育-光辉历程
2017-2018学年队前教育1光辉历程一、劳动童子团1924——1927二、三十年代年的中国是一个
【法律文书】 日期:2020-06-23
-
党支部1-12月全年主题党日活动计划表
2022年党支部主题党日活动计划表序号活动时间活动方式活动内容12022年1月专题学习研讨集中观看2022年新年贺词,积极开展学习研讨交流。组织生活会组织党员认真对照党章...
【活动总结】 日期:2022-10-14
-
【人教版1-6年级数学上册知识点精编】1-6年级数学人教版教材
人教版二年级数学上册知识点汇总第一单元长度单位一、米和厘米1、测量物体的长度时,要用统一的标准去测量
【调研报告】 日期:2020-11-08
-
2022年2月份主题党日活动记录5篇
2022年2月份主题党日活动记录5篇2022年2月份主题党日活动记录篇1尊敬的党组织:在今年的开学初,本人积极参加教研室组织的教研活动,在学校教研员的指
【活动总结】 日期:2022-08-12
-
医院最佳主题党日活动11篇
医院最佳主题党日活动11篇医院最佳主题党日活动篇1 医院最佳主题党日活动篇2为隆重纪念中国共产党成立100周年,进一步巩固党的群众路线教育实践活动成果,切实
【活动总结】 日期:2022-10-29
-
2023年平安校园建设方案13篇
平安校园建设方案“平安校园”创建工作,我们幼儿园全体教职员工一直把它当作头等大事来抓。领导高度重视,以“平安校园”创建活动为抓手,建立和规范校园安全工作机制
【规章制度】 日期:2023-11-02
-
主题党日活动记录202210篇
主题党日活动记录202210篇主题党日活动记录2022篇12021年是中国共产党成立100周年,为广泛开展爱国主义宣传教育,铭记党的历史,讴歌党的光辉历程,
【活动总结】 日期:2022-08-02
-
正式的晚宴邀请函 公司晚宴邀请函
尊敬的先生 女士: 我公司谨定于xxxx年xx月xx日xx:xx在xxxx店隆重举行xx市xx届xxxx晚宴(宴会地址:xx区xx路xxxx) 敬请届时光临!xxxxxx集团股份有限公司xxxx有限公司敬邀xxxx年xx月xx日
【简历资料】 日期:2019-08-03
-
《国行公祭,为佑世界和平》课文原文阅读_国行公祭为佑世界和平每段段意
国行公祭,为佑世界和平钟声“国行公祭,法立典章。铸兹宝鼎,祀我国殇。”侵华日军南京大屠杀遇难同胞纪念
【简历资料】 日期:2020-11-28
-
一年级新学期目标简短_一年级学生新学期打算
新学期到了,我是一年级下册的小学生了。 上课的时候,我要认真学习,不做小动作,认真听讲。我要认真学习,天天向上,努力学习,耳朵要听老师讲课,眼睛要瞪得大大的看老...
【简历资料】 日期:2019-10-26
-
[信访复查复核制度作用探讨]信访复查复核有用吗
作为我国特有的一项制度,信访制度的出现并长期存在不是偶然的,虽然一些法学专家认为信访制度具有“人治”
【职场指南】 日期:2020-02-16
-
[党员干部2019年主题教育个人问题检视清单及整改措施2篇] 党员干部
2019年主题教育问题检视清单及整改措施根据主题教育领导小组办公室《关于认真做好主题教育检视问题整改
【求职简历】 日期:2019-11-08
-
红旗颂朗诵稿原文【《红旗颂》朗诵词】
《红旗颂》朗诵词 女:晴空万里,红旗飘扬, 六十载风云,我们昂首阔步。 男:六十个春秋,
【职场指南】 日期:2020-02-16
-
网络维护工作内容_(精华)国家开放大学电大专科《网络系统管理与维护》形考任务1答案
国家开放大学电大专科《网络系统管理与维护》形考任务1答案形考任务1理解上网行为管理软件的功能【实训目
【职场指南】 日期:2020-07-17
-
党委会与局长办公会的区别_局长办公会制度
为进一步加强xxx局工作的规范化、制度化建设,提高行政效能,规范议事程序,特制定本制度。一、会议形式1、局长办公会议由局长、副局长参加。由局长召集和主持。根据工作需要...
【求职简历】 日期:2019-07-30
-
如何凝心聚力谋发展【坚定信心谋发展凝心聚力促跨越】
当前,清河正处于在苏北实现赶超跨越基础上全面腾飞的战略机遇期,处于在全市率先实现全面小康基础上率先实
【简历资料】 日期:2020-03-17
-
《铁拳砸碎“黑警伞”》警示教育片观后感
影片深刻剖析了广西北海市公安局海西派出所原所长张枭杰蜕变堕落的轨迹。观看警示教育片后,做为一名党员教
【简历资料】 日期:2020-08-17
-
“双一流”建设背景下河北省高校国有资产管理队伍建设研究
付彩霞黄尚东摘要:从“双一流”建设内涵和高校国有资产管理队伍改革着手,论“双一流”建设和高校国有资产
【其他范文】 日期:2022-12-28
-
外耳道真菌病的病原菌分布及疗效分析
贾雯,李灿,庞盼,李钰乐,张晓雪,曹永华,郭瑞林,(1 陕西中医药大学医学技术学院,陕西咸阳7120
【其他范文】 日期:2023-01-10
-
2022市委副书记市长在市优化营商环境联席会议上的讲话(完整)
同志们:刚刚闭幕的市第八次党代会,明确提出要打造X内最优营商环境的目标。今天开始的国务院大督查,也将深化“放管服”改革、优化营商环境作为这次大督查的重要内容,这些都...
【其他范文】 日期:2022-11-01
-
在全市人大人事代表工作座谈会上讲话
在全市人大人事代表工作座谈会上的讲话今天,我们在这里召开全市人大人事代表工作座谈会,主要任务是进一步深入落实市委、市人大常委会党组关于做好今年人大工作的要求,研究...
【其他范文】 日期:2022-09-18
-
生物分子学,第8章,杂交与芯片技术
第八章杂交与芯片技术学习目标掌握:1.核酸分子杂交的基本概念。2.探针的种类与标记方法。3.常见核酸
【口号大全】 日期:2020-10-13
-
碎片或其他(组诗)
刘娜水培的郁金香在办公室的嘈杂里无声向我倾斜请我看看,刚开的深紫色花朵皱缩成衰老子宫的叶正在腐烂的根
【其他范文】 日期:2023-06-30
-
“喜迎建团百年 争做时代青年”建团百年活动方案【优秀范文】
1922年,在中国***领导下,中国共产主义青年团成立。100年栉风沐雨,共青团始终坚定不移跟党走,团结带领广大团员青年前仆后继、砥砺奋进、勇当先锋,充分展现了党的助手和后...
【其他范文】 日期:2022-11-06
-
乡镇党委先进事迹材料:乡镇党委先进党组织
旧县镇位于马龙县的西部,介于曲靖市与昆明市两大城市之间,距曲靖42公里,昆明93公里,距马龙县城20公里,昆曲高速公路、昆沾铁路、宜马公路横穿全镇而过,是昆明进入曲靖的第...
【汇报体会】 日期:2019-07-27
-
贫困生补助申请书 [大一贫困生疫情助学生活金申请书]
大一贫困生疫情助学生活金申请书 尊敬的校领导: 您好! 我叫代林,我来自内蒙鄂伦春自治
【口号大全】 日期:2020-03-13
-
2022年全区企业家春节团拜会致辞讲话
各位领导、企业界的朋友们,女士们、先生们:今天,XX区对外投资和贸易企业家协会、青年企业家协会正式成立了。在此,我代表区委、区政府向当选的会长、执行会长、秘书长表示...
【其他范文】 日期:2022-10-08
-
理论中心组学习总体国家安全观发言材料9篇
理论中心组学习总体国家安全观发言材料9篇理论中心组学习总体国家安全观发言材料篇1(八)深入学习贯彻中央以及省的重要会议和文件精神深入学习贯彻年度内中央以
【发言稿】 日期:2022-08-04
-
军转座谈会交流发言4篇
军转座谈会交流发言4篇军转座谈会交流发言篇1大家好,我叫贺丽,2015届选调生,来自康定市委组织部,现在省委编办跟班学习。今天,非常荣幸向大家汇报我的学习收
【发言稿】 日期:2022-10-27
-
12岁生日小寿星发言4篇
12岁生日小寿星发言4篇12岁生日小寿星发言篇1各位来宾、各位朋友:大家好!今天,我们欢聚在这里,共同庆祝**十二周岁生日。首先,我代表**的父母以
【发言稿】 日期:2022-07-31
-
党内警告处分表态发言14篇
党内警告处分表态发言14篇党内警告处分表态发言篇1尊敬的各位领导、同事们:大家上午好!刚才会上宣布了党委关于我任职的决定,我首先衷心感谢党委的信任和
【发言稿】 日期:2022-09-13
-
党内警告处分党员讨论发言3篇
党内警告处分党员讨论发言3篇党内警告处分党员讨论发言篇1大家好!作为新时期的一名大学生,认真学习、深刻领会、全面贯彻省党代会精神,是当前和今后一个时期重
【发言稿】 日期:2022-08-07
-
廉政大会总结发言稿7篇
廉政大会总结发言稿7篇廉政大会总结发言稿篇1各位领导,同志们:根据会议安排,我就党风廉政建设工作做表态发言,不妥之处,请批评指正。一、提高认识,切实
【发言稿】 日期:2022-10-30
-
被约谈的表态发言8篇
被约谈的表态发言8篇被约谈的表态发言篇1各位领导、各位党员大家好:这天我能站在鲜红的党旗下,
【发言稿】 日期:2022-12-24
-
破冰提能大讨论个人发言4篇
破冰提能大讨论个人发言4篇破冰提能大讨论个人发言篇1党史学习教育开展以来,我坚持读原著、学原文、悟原理。今天,根据会议安排,现在我就“学史明理”主题谈几点个
【发言稿】 日期:2022-10-09
-
巡察整改专题民主生活会总结发言8篇
巡察整改专题民主生活会总结发言8篇巡察整改专题民主生活会总结发言篇1按照区委统一部署和纪监委、巡察办关于召开党史学习教育专题组织生活会的工作安排,近期我紧贴
【发言稿】 日期:2022-10-12
-
纪委书记工作表态发言4篇
纪委书记工作表态发言4篇纪委书记工作表态发言篇1在镇党委政府正确领导下,在全村干部和群众的共同努力下,紧紧围绕建设社会主义新农村工作为重点,尽职尽责,与时俱
【发言稿】 日期:2022-09-30
-
学习周永开先进事迹心得体会3篇
学习周永开先进事迹心得体会【一】通过学习周永开老先生先进事迹后,结合自己工作思考,感慨万千。同样作为
【格言】 日期:2021-04-10
-
最满意的三项工作200字【最新党办公务员副主任提拔考察个人三年思想工作总结报告】
党办公务员个人三年工作总结近三年来,本人在组织、领导的关心指导和同事们的团结协作下,尽快完成主角的转
【格言】 日期:2021-02-26
-
XX老干局推进党建与业务深度融合发展工作情况调研报告:党建调研报告
XX老干局推进党建与业务深度融合 发展工作情况的调研报告 党建工作与业务工作融合发展始终是一个充满生
【成语大全】 日期:2020-08-28
-
中国共产党第三代中央领导集体的卓越贡献
中国共产党第三代中央领导集体的卓越贡献 --------------继往开来铸就辉煌 【摘要】改
【成语大全】 日期:2020-03-20
-
信息技术2.0能力点 [全国中小学教师信息技术应用能力提升工程试题题库及参考答案「精编」]
全国中小学教师信息技术应用能力提升工程试题题库及答案(复习资料)一、判断题题库(A为正确,B为错误)
【格言】 日期:2020-11-17
-
党建工作运行机制内容有哪些_构建基层党建工作运行机制探讨
党的基层组织是党在社会基层组织中的战斗堡垒,是党的全部工作和战斗力的基础。加强和改进县级以下各类党的
【经典阅读】 日期:2020-01-22
-
电大现代教育原理_最新国家开放大学电大《现代教育原理》形考任务2试题及答案
最新国家开放大学电大《现代教育原理》形考任务2试题及答案形考任务二一、多项选择题(共17道试题,共3
【成语大全】 日期:2020-07-20
-
集合推理_七,推理与集合
七推理与集合1 期中考试数学成绩出来了,三个好朋友分别考了88分,92分,95分。他们分别考了多少分
【名人名言】 日期:2020-12-18
-
基层党务工作基本内容_党建基本工作有哪些
党建基本工作有哪些(一) 基层党建工作包括哪些内容 选择了大学生村官这条路,你就与农村基层党
【名人名言】 日期:2020-08-06
-
[人生赠言]城隍庙人生赠言注释
人之相惜惜于品,人之相敬敬于德,人之相交交于情,人之相随随于义,人之相拥拥于礼,人之相信信于诚,人之相伴伴于爱! 人生的确很累,看你如何品味,每天多寻欢乐,烦...
【格言】 日期:2019-07-14
-
关于三农工作重要论述心得体会3篇
关于三农工作重要论述心得体会3篇关于三农工作重要论述心得体会篇1习近平总书记指出:“建设现代化国家离不开农业农村现代化,要继续巩固脱贫攻坚成果,扎实推进乡村
【学习心得体会】 日期:2022-10-29
-
【福生庄隧道坍塌处理方案】 福生庄隧道在哪里
(呼和浩特铁路局大包电气化改造工程指挥部,内蒙古呼和浩特010050)摘要:文章介绍了福生庄隧道
【学习心得体会】 日期:2020-03-05
-
五个一百工程阅读心得体会13篇
五个一百工程阅读心得体会13篇五个一百工程阅读心得体会篇1凡益之道,与时偕行。在全国网络安全和信
【学习心得体会】 日期:2022-12-07
-
城管系统警示教育心得体会9篇
城管系统警示教育心得体会9篇城管系统警示教育心得体会篇1各党支部要召开多种形式的庆七一座谈会,组织广大党员进行座谈,回顾党的光辉历程,畅谈党的丰功伟绩,
【学习心得体会】 日期:2022-10-09
-
发展对象培训主要内容10篇
发展对象培训主要内容10篇发展对象培训主要内容篇1怀着无比激动的心情,我有幸参加了__新区区委党校20__年第四期(区级机关)党员发展对象培训班。这次的学习
【培训心得体会】 日期:2022-09-24
-
扶眉战役纪念馆心得体会11篇
扶眉战役纪念馆心得体会11篇扶眉战役纪念馆心得体会篇1有那么一段历史,低诉着血和泪的故事,慢慢地,随岁月老去;有那么一群人,放弃了闲逸的人生,辗转奔波中
【学习心得体会】 日期:2022-08-03
-
凝聚三种力量发展全过程人民民主心得体会12篇
凝聚三种力量发展全过程人民民主心得体会12篇凝聚三种力量发展全过程人民民主心得体会篇1新民主主义革命是指在帝国主义和无产阶级革命时代,殖民地半殖民地国家中的
【学习心得体会】 日期:2022-08-31
-
2022年全国检察长会议心得7篇
2022年全国检察长会议心得7篇2022年全国检察长会议心得篇1眼睛是心灵上的窗户,我们通过眼睛才能看到世间万物,才能看到眼前这美好的一切。拥有一双明亮的眼
【学习心得体会】 日期:2022-10-31
-
全面从严治党的心得体会800字7篇
全面从严治党的心得体会800字7篇全面从严治党的心得体会800字篇1中国特色社会主义是我们党领导
【学习心得体会】 日期:2022-12-14
-
教师全国两会精神学习专题研讨交流材料6篇
教师全国两会精神学习专题研讨交流材料6篇教师全国两会精神学习专题研讨交流材料篇1通过对两会精神深入系统的学习,作为新一代的青年人,更应该严格要求自己,贯彻落
【教师心得体会】 日期:2022-08-11
-
 2024年主题教育民主生活会批评与自我批评意见(38条)(范文推荐)
2024年主题教育民主生活会批评与自我批评意见(38条)(范文推荐)
2023年主题教育民主生活会六个方面个人检视、相互批评意见:1 理论学习系统性不强。学习习近平新时代中国特色社会主义思想不深不透,泛泛而学的时候多,深学细照的时候少,特...
【邓小平理论】 日期:2024-03-19
-
 2024年交流发言:强化思想理论武装,增强奋进力量(完整)
2024年交流发言:强化思想理论武装,增强奋进力量(完整)
习近平总书记指出:“一个民族要走在时代前列,就一刻不能没有理论思维,一刻不能没有思想指引。”党的十八大以来,伴随着新时代中国特色社会主义思想在实践中形成发展的历程...
【三个代表】 日期:2024-03-19
-
2024年度镇年度县乡人大代表述职评议活动总结
xx镇20xx年县乡人大代表述职评议活动总结为响应县级人大常委会关于开展县乡两级人大代表述职评议活动,进一步激发代表履职活力,加强代表与人民群众的联系,提高依法履职水平...
【马克思主义】 日期:2024-03-19
-
 “千万工程”经验学习体会(研讨材料)
“千万工程”经验学习体会(研讨材料)
“千万工程”是总书记在浙江工作时亲自谋划、亲自部署、亲自推动的一项重大决策,也是习近平新时代中国特色社会主义思想在之江大地的生动实践。20年来,“千万工程”先后经历...
【三个代表】 日期:2024-03-19
-
 2024年在市政协机关工作总结会议上讲话
2024年在市政协机关工作总结会议上讲话
同志们:刚才,XX同志对市政协机关20XX年工作进行了很好的总结,很精炼,很到位,可以感受到去年机关工作确实可圈可点。XX同志宣读了表彰决定,机关优秀人员代表、先进集体代...
【邓小平理论】 日期:2024-03-18
-
 在全区防汛防涝动员暨河长制工作推进会上讲话提纲【完整版】
在全区防汛防涝动员暨河长制工作推进会上讲话提纲【完整版】
区长,各位领导,同志们:汛期已经来临,我区城区防涝工作面临强大考验,形势不容乐观。年初,区城区防涝排渍指挥部已经召开专题调度会,修订完善应急预案,建立网格化管理机...
【马克思主义】 日期:2024-03-18
-
 2024年镇作风整治工作实施方案(完整文档)
2024年镇作风整治工作实施方案(完整文档)
XX镇作风整治工作实施方案为深入贯彻落实党的二十大精神及省市区委深化作风建设的最新要求,突出重点推进干部效能提升,坚持不懈推动作风整治工作纵深发展,根据《关于印发《2...
【毛泽东思想】 日期:2024-03-18
-
2024市优化法治化营商环境规范涉企行政执法实施方案【优秀范文】
xx市优化法治化营商环境规范涉企行政执法实施方案为持续优化法治化营商环境,激发市场主体活力和社会创造力,规范行政执法行为,创新行政执法方式,提升行政执法质效,着力解...
【毛泽东思想】 日期:2024-03-18
-
 2024年度关于开展新一轮思想状况摸底排查工作通知(完整)
2024年度关于开展新一轮思想状况摸底排查工作通知(完整)
关于开展新一轮思想状况摸底排查工作的通知为深入贯彻落实关于各地开展干部职工思想状况大摸底大排查情况上的批示要求和改革教育第二次调度会议精神,有针对性做好队伍教育管...
【三个代表】 日期:2024-03-18
-
2024年公路养护中心主任典型事迹材料(完整文档)
“中心的工作就是心中的事业”——公路养护中心主任典型事迹材料**,男,1976年6月出生,1993年参加工作,2000年4月调入**区交通运输局工作,大学本科学历,中共党员,现任**...
【马克思主义】 日期:2024-03-17