基于XLNet的中文文本情感分析
李东金,单 锐,*,阴良魁,王 芳,程宝娜
(1.燕山大学 理学院,河北 秦皇岛 066004;
2.中国科学院 科技创新发展中心,北京 100190)
随着网民数量的增加,越来越多的评论信息不断涌现。网民不仅可以在政府网站、微博等公众平台浏览每天发生的各类事件,还可以发表自己对这些事件的看法和态度。因此在这些平台中的存储了大量带有一定的情感倾向的文本。对这些文本进行深层次的提取,可以及时获取网民在这些评论文本中所表达的对各种热门事件和各种产品的看法和情感倾向,不仅可以使政府及时获取网络舆论情况,还可以使商家精准获得客户的需求。因此,随着自然语言处理技术的发展,可以从海量的评论文本中提取出评论者的情感倾向。
情感分析是通过一些特定的方法对评论的情感倾向进行判断,并根据判断的结果对文本进行分类,主要分为三个类别,基于情感词典的方法、基于机器学习的方法和基于深度学习的方法[1]。
基于情感词典的方法准确率主要和情感词典规模有关,因此模型往往只能针对某一领域有较好的结果,而对其他领域的情感分析较差,从而导致模型实时性不强[2]。基于机器学习的方法是构造分类器进行情感分析,Pang等[3]在对影评进行情感分析时,首次使用机器学习算法对文本情感进行分类,并在模型中结合了N-grams 模型和词性。相比于情感词典,机器学习方法相对情感词典方法有了一定的进步,但人为因素会对特征的选择产生一定的影响,且对于不同领域无法使用同一特征; 数据集的质量决定了分类器的效果,高质量的标注数据仍然需要人工大量构造[4]。而深度学习网络是通过模拟人的神经系统搭建的,所以其特征表示能力和分类能力更强于情感词典和机器学习[5]。基于深度学习的方法,都是将文本信息转换成序列化向量,通过神经网络对特征向量进行深层次的提取,并运用各种机制优化模型,从而得到了更高的准确率。Mikolov等[6]提出的 Word2vec,将每个词由k个维度的实值向量表示,使得Word2vec被广泛应用于情感分析领域。文献[7]通过Word2vec得到词向量,利用卷积神经网络(Convolutional Neural Network,CNN)对文本的局部特征进行提取,双向长短时记忆网络(Bi-directional Long Short-Term Memory, BiLSTM)则对文本的上下文特征进行提取,在一定程度上提高了文本情感分类的准确性。但是通过 Word2vec 得到的词向量无法解决相同词语在不同句子中可能具有不同的含意的问题。文献[8]提出了基于注意力机制的词表示方法,该方法利用《同义词词林扩展板》计算字词间的语义贡献度,并在数据集上验证了模型的有效率。文献[9]通过Word2vec获得初始词向量,并通过TF-IDF对文本情感影响程度不同的词汇赋予不同的权重值,以突出影响程度较大的词对文本的影响,从而取得了较高的准确率。
近年来,随着自然语言处理技术的发展,为了解决静态词向量模型的缺陷,研究者经过大量的研究提出了动态词向量表达。以此产生的模型有ELMo[10]、OpenAI GPT[11]、BERT[12]、XLNet[13]。由于静态词向量模型不能解决多义问题,文献[14]利用ELMo生成融合词语所在句子的上下文信息的词向量,并将其输入到改进的Transformer中,使模型提取到了更加丰富、全面的语义信息,从而获得了更高的准确率。文献[15]将ELMo和Glove获得的词向量进行堆叠嵌入,采用了CNN和双向门控循环单元 (Bi-directional Gated Recurrent Unit, BiGRU)的双通道神经网络模型,并通过仿真实验验证了模型的准确率。虽然ELMo由BiLSTM组成,这种方式在一定程度上同时利用了上下文信息,但只是对节点左右信息进行了拼接,其两边的信息并没有交集,因此ELMo并没有获得真正的上下文信息[16]。GPT预训练词向量模型为了获得长距离文本信息首次利用了Transformer网络。它虽然对ELMo进行了改进,但是GPT仍然是一种单向的语言模型,因此,仍然不可能为序列编码提供上下文信息。而BERT模型同样采用 Transformer 编码,BERT是在训练过程中对部分词语进行屏蔽来实现双向预测的。文献[17]以BERT模型为基础,引入了BiLSTM层和CRF层,使得模型可以通过上下文来判断情感倾向不明确的文本。虽然BERT在文本情感分析领域取得了不错成果,但也仍存在一定的缺陷,如预训练过程中的数据与微调的数据不匹配。XLNet模型的提出在一定程度上解决了BERT 模型存在的问题。XLNet模型和BERT模型的主要区别是:XLNet方法允许在双向上下文中训练模型,而无需像BERT方法那样屏蔽一部分预测词。文献[18]提出了基于XLNet和胶囊网络的模型,该模型采用带有动态路由算法的胶囊网络来提取文本的局部和空间层次关系,并产生局部特征表示,数据集测试表明,其性能优于BERT。文献[19]在XLNet的基础上增加了LSTM层和注意力机制,通过XLNet获取动态词向量,LSTM则用于提取上下文特征,最后再通过注意力机制,赋予特征不同的权重,该模型经过测试获得了较高的准确率。可以看出,XLNet预训练模型比其他词向量模型包含了更多的文本上下文语义信息,因此通过XLNet获得的动态词向量可以进一步提高模型的性能。
综上所述,本文提出了基于XLNet的文本情感分析模型。首先通过XLNet获得了包含文本上下文相关信息的词向量,在一定程度上改善一词多义问题;
其次利用CNN和BiGRU提取文本的局部和全局特征;
再通过注意力机制,对影响大的特征赋予较大权重,对影响较小的特征赋予较小权重;
最后,通过softmax分类器判断情感极性。
本文的主要工作如下:
1) 首先,对于文本向量化,本文采用预训练语言模型XLNet,以获得包含更多文本上下文语义信息的动态词向量,从而最大程度解决一词多义问题。
2) 其次,通过CNN和BiGRU对获得的词向量进行特征提取,获得了文本的局部和全局特征,使得模型能更好地理解文本的语义。
3) 最后利用注意力机制,对影响大的特征赋予较大权重,对影响较小的特征赋予较小权重,更加突出关键信息对文本的影响,降低噪声特征的干扰,从而进一步提高模型的准确率。
基于XLNet的文本情感分析模型主要由四部分组成,包括XLNet、CNN、BiGRU和注意力机制。本文模型如图1所示。

图1 XLNet-CNN-BiGRU-Att模型架构图Fig.1 Framework of XLNet-CNN-BiGRU-Att model
1.1 XLNet层
XLNet模型不仅具有 BERT模型的优点还对BERT模型的缺陷进行了改进,为了实现双向预测XLNet使用了三种机制:排列语言模型、双流自注意机制、循环机制[20]。
1.1.1 排列语言模型
现有的预训练模型可以分为自回归模型(autoregressive,AR)和自编码模型(autoencoding,AE)。AR模型可以根据上文情况预测下一个可能的单词,也可以通过下文预测上一个可能出现的单词,因此AR模型只考虑单向的文本信息,ELMo就是一个经典的自回归语言模型。而AE模型则通过对原句子进行破坏,并通过该模型来对原句子进行重构,将对受损部分重新预测,但在调优过程中实际数据中并不存在预训练时AE模型中使用的人工替换词,这将导致预训练和调优之间的差异。因此XLNet模型通过引入随机排序的思想,充分发挥了AR模型和AE模型的优点,又避免了他们的缺点。该思想获得序列的所有不同的排列,以获得不同的语序结构,通过学习不同排序的序列特征信息实现其双向预测的目标,同时不会改变原始词顺序。
但是对于一个长度为T的序列,其因式分解后的顺序有T!个,因此研究者对XLNet采取部分预测的方法进行优化。因此最终使得式(1)达到最优:

(1)
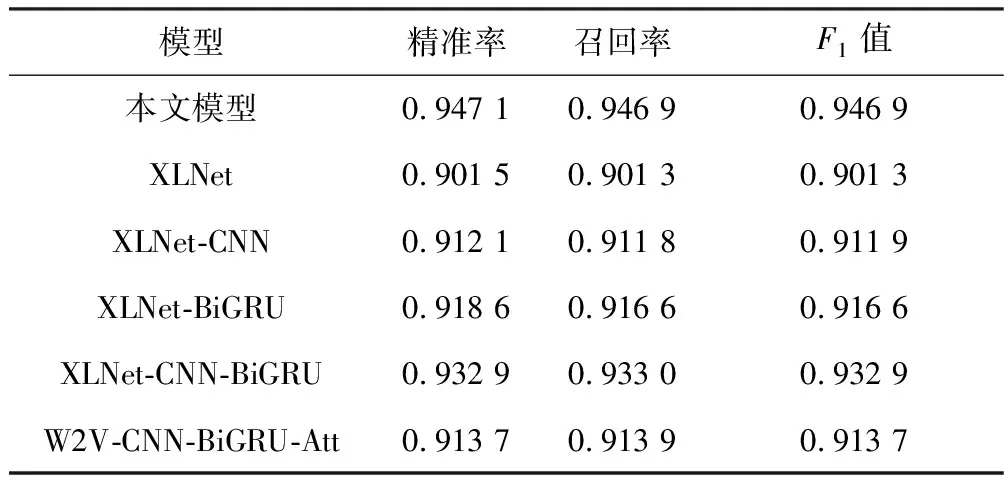
其中,T为该序列的所有不同顺序的集合,Z为集合T中的一种排列顺序,xzt表示顺序Z中第t个位置上的值,XZ 1.1.2 双流自注意机制 双流自注意机制的作用就是希望在预测xi时不仅要看到xi的位置信息还要获得其他词的位置和内容信息。双流自注意机制包括Query流和Content流。图2和图3是Query流和Content流的计算流程。其中Query流用g表示,Content流用h表示。 图2 Query流Fig.2 Query stream 图3 Content 流Fig.3 Content stream 根据Query流的工作原理,当预测某个词时,Q向量只包含该位置的位置信息,K和V则包含其他位置的内容信息,而对于Content 流,其与传统的transformer一样,同时编码了上下文和目标自身。 XLNet则是将Query 流和Content 流相结合,如图4所示。第一层将hi(0)和gi(0)分别初始化为e(xi)和W,然后使用Content掩码和Query掩码依次计算每一层的输出。 图4 双流自注意机制下的模型计算原理Fig.4 Principles of model computation under a two-stream self-attentive mechanism 1.1.3Transformer-XL 因为Transformer要求输入序列长度固定,这就使得长度小于所要求的固定长度时,需要对其进行填补,但长度大于固定长度则需要对序列进行分割处理,导致训练时失去部分信息。为了解决这样的问题,XLNet使用了 Transformer-XL 中循环机制和相对位置编码机制[21]。循环机制会在当前文本的计算中引入上一段文本输出的信息,使模型能够看到更多的上下文信息。由于引入了上一段文本的输出信息,可能使得位置编码相同但片段不同从而对当前片段的影响程度不同,所以引入了相对位置编码机制,该机制是将词语之间的相对位置应用于编码中。 综上所述,XLNet克服了自回归语言模型只考虑单项传递,没有充分利用上下文来提取更深层的信息,因此XLNet可以训练出更加完整的融合上下文信息的词向量。 本文模型应用卷积神经网络是为了对文本的局部特征进行提取,但由于本文设置BiGRU后连接全连接层和softmax分类器,故本文CNN主体由两部分构成:输入层、卷积层。 1) 输入层 本文采用XLNet对文本信息进行向量化,将输入的词向量用H∈Rk×n进行表示,其中k是句子的词向量个数,n代表词向量的维度。 2) 卷积层 卷积层使用固定尺寸的卷积核对输入的文本向量进行卷积运算,得到文本的局部特征信息[22]。卷积运算通常使用h×n维的过滤器,其中h和n分别表示卷积核尺寸和选取的词向量维度。 Cho等[23]在2014年提出了GRU网络模型,在GRU模型中只存在两个门:更新门和重置门。结构如图5所示。 图5 GRU结构Fig.5 GRU structure 图5中zt和rt分别表示GRU模型中的更新门和重置门。其计算公式为 rt=σWrxt+Urht-1 (2) zt=σWzxt+Uzht-1 (3) (4) (5) 由于单向GRU网络在时刻t只能捕捉t时刻之前的历史信息,所以只通过单向GRU是无法获得文本上下文信息的。为了实现这一目的本文采用双向门控循环单元。BiGRU网络模型的具体结构如图6所示。 图6 BiGRU神经网络模型Fig.6 BiGRU neural network model 文本向量分别以正向和反向的顺序通过前向GRU和后向GRU,因此通过BiGRU每一时刻得到的文本特征信息都包括上文与下文之间的相关性。计算公式为 (6) (7) (8) 注意力机制通过对文本向量分配不同的权重,更加突出文本中更重要的信息,并减少次要信息的干扰,提高分类的准确率[24]。因为对于每个句子,不同的词对句子的影响程度不同,因此,本文引入了一种注意力机制。注意力机制本质上就是Query到一系列键值对(Key-Value)上的映射函数,其计算流程如图7所示。 图7 注意力机制计算流程Fig.7 Attention mechanism calculation process 本文模型的参数如表1所示。 表1 XLNet-CNN-BiGRU-Att模型参数设置Tab.1 Parameter settings of XLNet-CNN-BiGRU-Att model 本文采用谭松波酒店评论数据集,包含6 000条语料,按照积极和消极分为两类,积极语料包括3 000条,消极语料包括3 000条。本实验将随机抽取70%的数据集作为训练集,另外的30%作为测试集。其中积极评价用标签1表示,消极评价用标签0表示。 本文模型以keras架构实现,通过Anaconda平台采用Python语言进行验证,操作系统为Windows 10家庭版,CPU为Intel Core i5-11260H @ 2.60 GHz,硬盘为1 TB,内存为32 GB。 本文模型性能将由精准率P、召回率R和F1值3个指标进行评估,其计算公式为 (9) (10) (11) 式中:nTP为把标签为1的文本判断成标签为1的文本的数量; 本文设置了多组实验进行对比,其中包括单一模型和联合模型的比较、静态词向量模型和动态词向量模型的比较。其中前五个模型均用XLNet预训练语言模型获得词向量,而最后的模型采用Word2vec模型获得词向量。 1) XLNet:单一的XLNet模型。 2) CNN:单一的CNN模型。 3) BiGRU:单一的BiGRU模型。 4) CNN-BiGRU:在XLNet的基础上先添加CNN模型,在CNN后加入BiGRU模型,最后接softmax分类器。 5) W2V-CNN-BiGRU-Att:首先通过Word2vec获得词向量,依次连接CNN模型、BiGRU模型和注意力机制。 经过测试集测试,本文模型与其他5种模型的结果对比如表2所示。 表2 模型对比结果Tab.2 Comparison results of models 从表2中6组模型的3个指标对比结果可以看出,本文模型的分类效果更好。首先第2和5组模型对比可以得出CNN和BiGRU均对文本情感分析产生了正向影响。其次第3、4、5组模型对比体现出了 CNN-BiGRU联合模型的优点,CNN-BiGRU联合模型可以同时获得文本的局部和全局信息,其中第3组单CNN模型只考虑了文本局部信息对情感分析的影响,忽略了全局信息的影响,而第4组模型只考虑了全局信息的影响,忽略了局部信息的影响,因此第3组和第4组模型准确率、召回率和F1值均低于第5组模型。再次第5组模型和本文模型相比,体现出了在联合模型之后连接注意力机制可以有效提升模型的准确率,因为注意力机制会对贡献度不同的特征赋予不同的权重,会更加突出重要特征的影响,使得模型具有更高的准确率。最后由于XLNet预训练语言模型可以获得真正的融合上下文语义的词向量,即相同的词语在不同语义下会得到不同的词向量,而Word2vec对不同语义下的同一词语赋予的词向量是完全相同的,因此最后一组模型的精确率、召回率和F1值均低于本文模型。综上所述,本文模型具有良好的性能和泛化能力。 本文在XLNet预训练语言模型的基础上加入了卷积神经网络、双向门控循环网络和注意力机制,不仅解决了传统词向量模型的一词多义问题,而且同时提取了文本的全局与局部信息,此外注意力机制还加强了重要特征对文本分类的影响,有效地提高了模型的准确率。通过对比实验,本文模型各种评估指标均有一定的提升。由于本文只将文本分为积极和消极两类,因此文本情感细粒度是下一步研究的重点。


1.2 卷积神经网络
1.3 BiGRU层







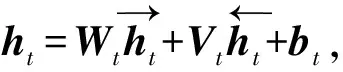

1.4 注意力机制

2.1 实验条件

2.2 评估指标



nFP是把标签为0的文本错判成标签为1的文本的数量;
nFN是把标签为1的文本错判成标签为0的文本的数量。2.3 对比实验设置
2.4 实验结果分析
- 范文大全
- 说说大全
- 学习资料
- 语录
- 生肖
- 解梦
- 十二星座
-
2022年4月主题党日活动记录范文15篇
2022年4月主题党日活动记录范文15篇2022年4月主题党日活动记录范文篇1一个崇尚阅读的民族,必然精神饱满、意气风发、活力四射。习近平总书记强调:“学习
【活动总结】 日期:2022-08-01
-
少先队的光荣历史故事 队前教育-光辉历程
2017-2018学年队前教育1光辉历程一、劳动童子团1924——1927二、三十年代年的中国是一个
【法律文书】 日期:2020-06-23
-
家乡赋|最美的家乡赋
家乡赋 孙传志 今安康市,白河双丰镇,吾之家乡也。三环沃土,山水环抱。其北依山,山系五岭,山
【调研报告】 日期:2020-04-01
-
党支部1-12月全年主题党日活动计划表
2022年党支部主题党日活动计划表序号活动时间活动方式活动内容12022年1月专题学习研讨集中观看2022年新年贺词,积极开展学习研讨交流。组织生活会组织党员认真对照党章...
【活动总结】 日期:2022-10-14
-
【人教版1-6年级数学上册知识点精编】1-6年级数学人教版教材
人教版二年级数学上册知识点汇总第一单元长度单位一、米和厘米1、测量物体的长度时,要用统一的标准去测量
【调研报告】 日期:2020-11-08
-
2022年2月份主题党日活动记录5篇
2022年2月份主题党日活动记录5篇2022年2月份主题党日活动记录篇1尊敬的党组织:在今年的开学初,本人积极参加教研室组织的教研活动,在学校教研员的指
【活动总结】 日期:2022-08-12
-
2023年平安校园建设方案13篇
平安校园建设方案“平安校园”创建工作,我们幼儿园全体教职员工一直把它当作头等大事来抓。领导高度重视,以“平安校园”创建活动为抓手,建立和规范校园安全工作机制
【规章制度】 日期:2023-11-02
-
医院最佳主题党日活动11篇
医院最佳主题党日活动11篇医院最佳主题党日活动篇1 医院最佳主题党日活动篇2为隆重纪念中国共产党成立100周年,进一步巩固党的群众路线教育实践活动成果,切实
【活动总结】 日期:2022-10-29
-
南京大屠杀国家公祭日悼念文案句子11篇
南京大屠杀国家公祭日悼念文案精选句子1、惟有民魂是值得宝贵的,惟有他发扬起来,中国才有真进步。——鲁迅2、我爱我的祖国,爱我的人民,离开了它,离开了他们,我
【企划文案】 日期:2023-10-20
-
主题党日活动记录202210篇
主题党日活动记录202210篇主题党日活动记录2022篇12021年是中国共产党成立100周年,为广泛开展爱国主义宣传教育,铭记党的历史,讴歌党的光辉历程,
【活动总结】 日期:2022-08-02
-
入少先队员改正的缺点有哪些_少先队申请书
敬爱的少先队组织:我们是共产主义接班人,继承革命先辈的光荣传统,爱祖国,爱人民,鲜艳的红领巾飘扬在前胸 我叫xx,是一年级(x)班的小学生。每当听到这首...
【简历资料】 日期:2019-07-28
-
正式的晚宴邀请函 公司晚宴邀请函
尊敬的先生 女士: 我公司谨定于xxxx年xx月xx日xx:xx在xxxx店隆重举行xx市xx届xxxx晚宴(宴会地址:xx区xx路xxxx) 敬请届时光临!xxxxxx集团股份有限公司xxxx有限公司敬邀xxxx年xx月xx日
【简历资料】 日期:2019-08-03
-
一年级新学期目标简短_一年级学生新学期打算
新学期到了,我是一年级下册的小学生了。 上课的时候,我要认真学习,不做小动作,认真听讲。我要认真学习,天天向上,努力学习,耳朵要听老师讲课,眼睛要瞪得大大的看老...
【简历资料】 日期:2019-10-26
-
[信访复查复核制度作用探讨]信访复查复核有用吗
作为我国特有的一项制度,信访制度的出现并长期存在不是偶然的,虽然一些法学专家认为信访制度具有“人治”
【职场指南】 日期:2020-02-16
-
[党员干部2019年主题教育个人问题检视清单及整改措施2篇] 党员干部
2019年主题教育问题检视清单及整改措施根据主题教育领导小组办公室《关于认真做好主题教育检视问题整改
【求职简历】 日期:2019-11-08
-
网络维护工作内容_(精华)国家开放大学电大专科《网络系统管理与维护》形考任务1答案
国家开放大学电大专科《网络系统管理与维护》形考任务1答案形考任务1理解上网行为管理软件的功能【实训目
【职场指南】 日期:2020-07-17
-
党委会与局长办公会的区别_局长办公会制度
为进一步加强xxx局工作的规范化、制度化建设,提高行政效能,规范议事程序,特制定本制度。一、会议形式1、局长办公会议由局长、副局长参加。由局长召集和主持。根据工作需要...
【求职简历】 日期:2019-07-30
-
学生会组织部部长竞选稿5篇
学生会组织部部长竞选稿以“三制”为统领推进农村党的建设中共**市委组织部近年来,**市认真落实中央、省和徐州市委的部署,积极适应发展要求,从加强领导体制、运
【求职简历】 日期:2023-11-06
-
如何凝心聚力谋发展【坚定信心谋发展凝心聚力促跨越】
当前,清河正处于在苏北实现赶超跨越基础上全面腾飞的战略机遇期,处于在全市率先实现全面小康基础上率先实
【简历资料】 日期:2020-03-17
-
《铁拳砸碎“黑警伞”》警示教育片观后感
影片深刻剖析了广西北海市公安局海西派出所原所长张枭杰蜕变堕落的轨迹。观看警示教育片后,做为一名党员教
【简历资料】 日期:2020-08-17
-
烟草改革 基层烟草企业职工培训工作的思考
基层烟草企业职工培训工作的思考 企业的发展,关键在于“人”,而“人”的综合素质的提高,又关键在
【节日庆典】 日期:2020-03-24
-
杭州市2019-2020学年三年级上册数学期末模拟卷(三)C卷_三上期末数学试卷
杭州市2019-2020学年三年级上册数学期末模拟卷(三)C卷姓名:________班级:_____
【礼仪】 日期:2020-09-22
-
三年级下册数学学案-6.3比大小北师大版|
北师大版数学三年级下册第第六单元第三课时教学设计课题比大小单元第六单元学科数学年级三年级学习目标1、
【毕业论文】 日期:2021-05-17
-
法院少年庭【法院少年庭2012年述职报告】
xx年以来,在市创建优秀“青少年维权岗”活动领导小组及院党组的正确领导下,认真贯彻执行“教育、感化、挽救”方针,积极探索新形势下审理未成年人犯罪案件的方式方法,不断...
【礼仪】 日期:2019-07-22
-
1种三氟甲基磺酰氟合成新方法
徐锋,代现跃,李志永,金利文,赵洁(浙江巨化技术中心有限公司,国家氟材料工程技术研究中心,浙江衢州3
【其他范文】 日期:2023-02-24
-
动物疫病防控中产地检疫程序及措施
摘要:充分落实动物疫病检疫,能有效提升畜禽养殖效益,提高肉类产品质量安全。作为检疫工作中的核心环节,
【其他范文】 日期:2022-12-27
-
全面从严治党的着力点12篇
全面从严治党的着力点12篇全面从严治党的着力点篇120_年1月12日至14日,中国共产党第_届中央纪律检查委员会第六次全体会议在北京召开。出席全会并发表重要
【其他范文】 日期:2022-10-20
-
2022县委换届工作情况报告(2022年)
下面是小编为大家整理的2022县委换届工作情况报告(2022年)文章,仅供
【其他范文】 日期:2022-09-05
-
7篇县委常委副县长换届选举提拔考察个人五年工作总结现实表现材料_
XX同志现实表现材料(县委常委)1 一、党性修养强,理论水平高,政治信念坚定。该同志始终把忠诚干净
【汇报体会】 日期:2021-06-10
-
改善农村人居环境_乡2020年农村人居环境整治农户家庭卫生星级创评工作实施方案
XX乡2020年农村人居环境整治农户家庭卫生星级创评工作实施方案为深入贯彻落实中央、省、市、县关于农
【节日庆典】 日期:2020-10-17
-
军转座谈会交流发言4篇
军转座谈会交流发言4篇军转座谈会交流发言篇1大家好,我叫贺丽,2015届选调生,来自康定市委组织部,现在省委编办跟班学习。今天,非常荣幸向大家汇报我的学习收
【发言稿】 日期:2022-10-27
-
12岁生日小寿星发言4篇
12岁生日小寿星发言4篇12岁生日小寿星发言篇1各位来宾、各位朋友:大家好!今天,我们欢聚在这里,共同庆祝**十二周岁生日。首先,我代表**的父母以
【发言稿】 日期:2022-07-31
-
廉政大会总结发言稿7篇
廉政大会总结发言稿7篇廉政大会总结发言稿篇1各位领导,同志们:根据会议安排,我就党风廉政建设工作做表态发言,不妥之处,请批评指正。一、提高认识,切实
【发言稿】 日期:2022-10-30
-
【企业疫情风险控制方案】 2020企业复工疫情方案
企业疫情风险控制方案2020新冠病毒肺炎疫情防控工作总结汇报3篇 关于新型冠状病毒感染的肺炎疫
【演讲稿】 日期:2020-02-27
-
纪委书记工作表态发言4篇
纪委书记工作表态发言4篇纪委书记工作表态发言篇1在镇党委政府正确领导下,在全村干部和群众的共同努力下,紧紧围绕建设社会主义新农村工作为重点,尽职尽责,与时俱
【发言稿】 日期:2022-09-30
-
党员教育培训总结交流发言12篇
党员教育培训总结交流发言12篇党员教育培训总结交流发言篇1根据市委组织部《关于开展我市〈20XX
【发言稿】 日期:2022-12-19
-
我最敬佩的人开头_我敬佩的一个人作文20篇2020年
我敬佩的一个人作文20篇 我敬佩的一个人作文一): 我身边有很多值得我们敬佩的人,但我最敬佩的一
【发言稿】 日期:2020-11-10
-
[钻井队队长(副队长、指导员)岗位HSE应知应会试题(1863)]
钻井队队长(副队长、指导员)岗位HSE应知应会试题(判断题:771;单选题:626;多选题:466)
【贺词】 日期:2020-09-23
-
话剧《家》剧本 话剧剧本:爱的空间
找文章到更多原创-(http: www damishu cn)人物介绍:刘伟,男,32岁,某购物广
【演讲稿】 日期:2020-01-21
-
五言绝句大全500首古诗_五言绝句144首
五言绝句144首 五言绝句(一): 1《春夜喜雨》唐朝·杜甫 好雨知时节,当春乃发生。随风潜入
【祝福语】 日期:2021-03-13
-
2023年中国行政区划调整方案(设想优秀3篇
中国行政区划调整方案(设想优秀民政部第二次行政区划研讨会会议内容一、缩省的意义与原则1.意义1)利于减少中间层次中国行政区划层级之多为世界之最,既使管理成本
【周公解梦】 日期:2024-02-20
-
2023年和儿媳妇在一起幸福的句子3篇
和儿媳妇在一起幸福的句子1、假如人生不曾相遇,我还是那个我,偶尔做做梦,然后,开始日复一日的奔波,淹没在这喧嚣的城市里。我不会了解,这个世界还有这样的一个你
【格言】 日期:2023-11-10
-
XX老干局推进党建与业务深度融合发展工作情况调研报告:党建调研报告
XX老干局推进党建与业务深度融合 发展工作情况的调研报告 党建工作与业务工作融合发展始终是一个充满生
【成语大全】 日期:2020-08-28
-
中国共产党第三代中央领导集体的卓越贡献
中国共产党第三代中央领导集体的卓越贡献 --------------继往开来铸就辉煌 【摘要】改
【成语大全】 日期:2020-03-20
-
信息技术2.0能力点 [全国中小学教师信息技术应用能力提升工程试题题库及参考答案「精编」]
全国中小学教师信息技术应用能力提升工程试题题库及答案(复习资料)一、判断题题库(A为正确,B为错误)
【格言】 日期:2020-11-17
-
党建工作运行机制内容有哪些_构建基层党建工作运行机制探讨
党的基层组织是党在社会基层组织中的战斗堡垒,是党的全部工作和战斗力的基础。加强和改进县级以下各类党的
【经典阅读】 日期:2020-01-22
-
电大现代教育原理_最新国家开放大学电大《现代教育原理》形考任务2试题及答案
最新国家开放大学电大《现代教育原理》形考任务2试题及答案形考任务二一、多项选择题(共17道试题,共3
【成语大全】 日期:2020-07-20
-
集合推理_七,推理与集合
七推理与集合1 期中考试数学成绩出来了,三个好朋友分别考了88分,92分,95分。他们分别考了多少分
【名人名言】 日期:2020-12-18
-
基层党务工作基本内容_党建基本工作有哪些
党建基本工作有哪些(一) 基层党建工作包括哪些内容 选择了大学生村官这条路,你就与农村基层党
【名人名言】 日期:2020-08-06
-
【2020-2021学年高一英语外研版(2019)选择性必修第一册Unit3Faster,higher,strongerSectionⅠ导学讲义】
Unit3 Faster,higher,stronger背景导学MichaelJordan—Head
【歇后语】 日期:2021-04-19
-
关于三农工作重要论述心得体会3篇
关于三农工作重要论述心得体会3篇关于三农工作重要论述心得体会篇1习近平总书记指出:“建设现代化国家离不开农业农村现代化,要继续巩固脱贫攻坚成果,扎实推进乡村
【学习心得体会】 日期:2022-10-29
-
【福生庄隧道坍塌处理方案】 福生庄隧道在哪里
(呼和浩特铁路局大包电气化改造工程指挥部,内蒙古呼和浩特010050)摘要:文章介绍了福生庄隧道
【学习心得体会】 日期:2020-03-05
-
五个一百工程阅读心得体会13篇
五个一百工程阅读心得体会13篇五个一百工程阅读心得体会篇1凡益之道,与时偕行。在全国网络安全和信
【学习心得体会】 日期:2022-12-07
-
城管系统警示教育心得体会9篇
城管系统警示教育心得体会9篇城管系统警示教育心得体会篇1各党支部要召开多种形式的庆七一座谈会,组织广大党员进行座谈,回顾党的光辉历程,畅谈党的丰功伟绩,
【学习心得体会】 日期:2022-10-09
-
发展对象培训主要内容10篇
发展对象培训主要内容10篇发展对象培训主要内容篇1怀着无比激动的心情,我有幸参加了__新区区委党校20__年第四期(区级机关)党员发展对象培训班。这次的学习
【培训心得体会】 日期:2022-09-24
-
凝聚三种力量发展全过程人民民主心得体会12篇
凝聚三种力量发展全过程人民民主心得体会12篇凝聚三种力量发展全过程人民民主心得体会篇1新民主主义革命是指在帝国主义和无产阶级革命时代,殖民地半殖民地国家中的
【学习心得体会】 日期:2022-08-31
-
2022年全国检察长会议心得7篇
2022年全国检察长会议心得7篇2022年全国检察长会议心得篇1眼睛是心灵上的窗户,我们通过眼睛才能看到世间万物,才能看到眼前这美好的一切。拥有一双明亮的眼
【学习心得体会】 日期:2022-10-31
-
在街道深化作风建设推动高质量发展走在前列动员会上讲话
在2023年街道深化作风建设推动高质量发展走在前列动员会上的讲话同志们:今天我们召开“街道深化作风建设推动高质量发展走在前列动员会”,这次会议是街道三季度召开的第一场...
【军训心得体会】 日期:2024-03-17
-
全面从严治党的心得体会800字7篇
全面从严治党的心得体会800字7篇全面从严治党的心得体会800字篇1中国特色社会主义是我们党领导
【学习心得体会】 日期:2022-12-14
-
2月教师党员个人思想汇报5篇
2月教师党员个人思想汇报敬爱的党组织:最近这一个月的时间对于我来说是极不平凡的,在这段时间里我认真学习了文化部网上党校的相关内容,经过长达40小时的
【教师心得体会】 日期:2023-10-15
-
 2024年主题教育民主生活会批评与自我批评意见(38条)(范文推荐)
2024年主题教育民主生活会批评与自我批评意见(38条)(范文推荐)
2023年主题教育民主生活会六个方面个人检视、相互批评意见:1 理论学习系统性不强。学习习近平新时代中国特色社会主义思想不深不透,泛泛而学的时候多,深学细照的时候少,特...
【邓小平理论】 日期:2024-03-19
-
 2024年交流发言:强化思想理论武装,增强奋进力量(完整)
2024年交流发言:强化思想理论武装,增强奋进力量(完整)
习近平总书记指出:“一个民族要走在时代前列,就一刻不能没有理论思维,一刻不能没有思想指引。”党的十八大以来,伴随着新时代中国特色社会主义思想在实践中形成发展的历程...
【三个代表】 日期:2024-03-19
-
2024年度镇年度县乡人大代表述职评议活动总结
xx镇20xx年县乡人大代表述职评议活动总结为响应县级人大常委会关于开展县乡两级人大代表述职评议活动,进一步激发代表履职活力,加强代表与人民群众的联系,提高依法履职水平...
【马克思主义】 日期:2024-03-19
-
 “千万工程”经验学习体会(研讨材料)
“千万工程”经验学习体会(研讨材料)
“千万工程”是总书记在浙江工作时亲自谋划、亲自部署、亲自推动的一项重大决策,也是习近平新时代中国特色社会主义思想在之江大地的生动实践。20年来,“千万工程”先后经历...
【三个代表】 日期:2024-03-19
-
 2024年在市政协机关工作总结会议上讲话
2024年在市政协机关工作总结会议上讲话
同志们:刚才,XX同志对市政协机关20XX年工作进行了很好的总结,很精炼,很到位,可以感受到去年机关工作确实可圈可点。XX同志宣读了表彰决定,机关优秀人员代表、先进集体代...
【邓小平理论】 日期:2024-03-18
-
 在全区防汛防涝动员暨河长制工作推进会上讲话提纲【完整版】
在全区防汛防涝动员暨河长制工作推进会上讲话提纲【完整版】
区长,各位领导,同志们:汛期已经来临,我区城区防涝工作面临强大考验,形势不容乐观。年初,区城区防涝排渍指挥部已经召开专题调度会,修订完善应急预案,建立网格化管理机...
【马克思主义】 日期:2024-03-18
-
 2024年镇作风整治工作实施方案(完整文档)
2024年镇作风整治工作实施方案(完整文档)
XX镇作风整治工作实施方案为深入贯彻落实党的二十大精神及省市区委深化作风建设的最新要求,突出重点推进干部效能提升,坚持不懈推动作风整治工作纵深发展,根据《关于印发《2...
【毛泽东思想】 日期:2024-03-18
-
2024市优化法治化营商环境规范涉企行政执法实施方案【优秀范文】
xx市优化法治化营商环境规范涉企行政执法实施方案为持续优化法治化营商环境,激发市场主体活力和社会创造力,规范行政执法行为,创新行政执法方式,提升行政执法质效,着力解...
【毛泽东思想】 日期:2024-03-18
-
 2024年度关于开展新一轮思想状况摸底排查工作通知(完整)
2024年度关于开展新一轮思想状况摸底排查工作通知(完整)
关于开展新一轮思想状况摸底排查工作的通知为深入贯彻落实关于各地开展干部职工思想状况大摸底大排查情况上的批示要求和改革教育第二次调度会议精神,有针对性做好队伍教育管...
【三个代表】 日期:2024-03-18
-
2024年公路养护中心主任典型事迹材料(完整文档)
“中心的工作就是心中的事业”——公路养护中心主任典型事迹材料**,男,1976年6月出生,1993年参加工作,2000年4月调入**区交通运输局工作,大学本科学历,中共党员,现任**...
【马克思主义】 日期:2024-03-17