融合语句复杂度的软件错误定位轻量级方法*
何海江
(长沙学院计算机工程与应用数学学院,湖南 长沙 410022)
调试和测试是软件生命周期中的重要活动,这其间,开发人员为移除软件故障,耗时且费力。软件出现故障,首要任务是找到导致出错的代码。代码审查和静态检查固然是有效的故障定位方法,但前者人工耗费大,后者难以发现深层次的逻辑错误。VS Code、IDEA和Eclipse等开发平台提供的断点调试方法,不能确定代码检查顺序,完全依赖程序员的编程经验来查找错误。因此,人们开始研究自动化的软件错误定位[1,2]技术,其中基于程序谱的软件错误定位SBFL(Spectrum-Based Fault Localization)技术最受关注。现代软件的规模越来越大,而CPU、内存等资源始终受到限制,SBFL这一类轻量级方法更有实用价值。
SBFL可应用于文件、类、方法(函数)、代码片段、语句(代码行)和谓词等程序实体。本文聚焦于语句级故障定位,只讨论相关技术。人们提出了许多SBFL方法[2],然而,这些方法在定位故障语句时,仅考察语句覆盖结果和测试用例通过与否,故而其性能受到限制。为克服这一缺陷,一系列结合程序谱、代码静态特征、代码动态特征的搜索方法[3]得到发展。然而,这些方法要么获取程序特征的代价大,要么只在方法级、类级和文件级上验证性能。
为了能轻量地定位到故障语句,本文提出了一种语句级软件错误定位的排序学习方法。在表征语句时,除语句的SBFL可疑度值外,还选择了3类轻量级特征:(1)局部变量数、逻辑操作符数和函数调用数等语句静态属性;
(2)结构化类别;(3)变量谱。在排序学习过程中,使用跨项目的方式训练排序模型。数据集包含使用Java、C和C++ 编程语言开发的22个项目,包括753个带故障的版本,故障语句全部来源于程序员实际的编程活动,项目规模有大有小,版本所含错误个数有多有少。实验结果表明,将SBFL可疑度值分别与3类语句特征结合后,即使与表现最佳的SBFL方法相比,新方法都能大幅度减少待排查的语句。3类轻量级特征中,尤以语句静态属性最能改善错误定位模型的性能。同时也发现,一些在小规模数据集或者人工注入故障版本上得到验证的SBFL方法,表现并不好。
基于程序谱的软件错误定位技术仅需收集2类信息:(1)测试用例的执行结果:成功或失败;
(2)程序运行时,是否覆盖语句。形式上,每条可执行语句的运行特征可用四元组〈aep,aef,anp,anf〉表示。对程序的每一条语句,aep和aef分别表示测试用例覆盖它并且程序运行结果成功或失败的数目;
anp和anf则分别表示测试用例未覆盖它并且程序运行结果成功或失败的个数。
SBFL方法将程序谱转换成不同的语句可疑度计算公式(简称为SBFL公式)。SBFL公式可看作映射函数,将特征向量映射成一个实数值(可疑度值)。当故障发生时,依据这些映射函数逐一计算可执行语句的可疑度值,将语句按照可疑度从大到小排序。排查故障代码时,从顺序表顶端开始逐一排查语句,直到发现错误代码。
DStar2[4]、GP02[5]、GP10[5]、GP13[5]、Tarantula[6]、Ochiai[6]、NaishO[7](即Naish1[8])、NaishOp[7](即Naish2[8])、Wong1[9]、Wong2[9]、Wong3[9]、SBI、Overlap、RussellRao、Jaccard、Dice、Zoltar、M2、Goodman、Anderberg、Kulczynski1、Kulczynski2和Ample,都是研究人员提出的SBFL公式。SBI公式在文献[10]中有相应的描述;
从Overlap到Ample,这11个公式在文献[7,8]中有相应的描述。
Tarantula、Zoltar、Kulczynski2、RusselRao、Ochiai、Ample、M2、Jaccard 和Anderberg,这9个SBFL公式的值都处于0~1,其余14个SBFL公式的值可归一化到[0,1]。例如式(1)是Overlap公式常规的计算方法,其值区间为[0,+∞),经过式(2)的归一化处理后,其值区间为[0,1]。
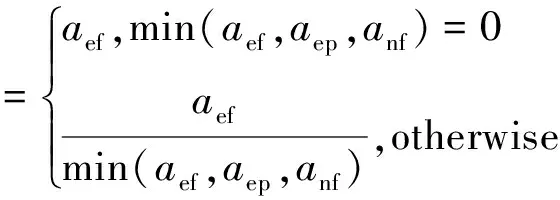
(1)
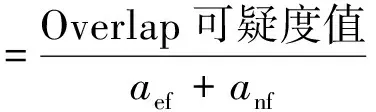
(2)
Lucia 等人[11]对比了将近40 种SBFL,发现Ochiai公式的故障定位能力相对突出,任何一种SBFL方法都无法在多数项目(程序)中超过其它方法。Pearson等人[12]在6个项目、323个版本的实际故障数据集上的实验数据也证实了这一点。
特定的项目,受软件规模、测试套件、单个或多个故障、编程语言等因素的影响,可能出错方式与其它项目迥异。以表征语句可疑度的SBFL公式为特征集,机器学习技术可为项目搜索到对应的最优故障代码判别模型。MULTRIC(MULtiple ranking meTRICs for fault localization)[13]组合25个SBFL公式,LTR-sbfl[14]将非故障语句与故障语句两两组合成复合样本,再由排序学习算法训练映射函数。然而,这些方法和传统的SBFL方法相似,可疑度只依赖于测试用例执行结果和程序实体覆盖信息,错误定位效果受到严重制约。若要提升性能,程序逻辑复杂度、故障语句类型和测试用例集等因素都应该考虑。由此,研究人员拓宽思路,引入表征软件的其它视角的数据,开发了许多基于搜索的软件错误定位方法[3]。
这些搜索技术的特征,除SBFL公式外,还包括:多个变异技术、源代码复杂度和文本相似性特征[10],方法存在时长、程序元素改变频率等代码变化测度[15],函数级代码复杂度[16],长短期记忆网络自动化学习代码的语义特征[17],项目开发报告形成的历史谱[18],语句类别[19]和测试用例的全部覆盖信息[20]。PRINCE(PRecise machINe-learning-based fault loCalization tEchnique)和CombineFL[21,22]综合多类特征,集成SBFL、变异测度、切片、栈跟踪、谓词变化、代码复杂度、故障报告和开发历史,比较这些静态特征和动态特征对排序学习算法训练模型的影响程度。但是,这些方法多用于文件级、类级和方法级(函数级)故障定位,大部分方法的语句级特征获取代价大。
调试时,程序员需要定位到故障语句,不能仅限于类或方法。自动化程序软件修复[1]这类应用也只能运用语句级故障定位技术。同时,为使得技术能应用到代码量具有一定规模的工业软件,本文聚焦于语句级的轻量方法,要求代码特征及可疑度值的计算代价极小。受到搜索式软件错误定位和软件复杂性度量研究工作[23]的启发,本文提出了一种集成程序谱和代码行静态属性的排序学习方法,由线性排序支持向量机构造语句级的错误定位模型。语句的其它轻量特征:结构化类别和变量谱,也能够方便地集成到搜索算法中。
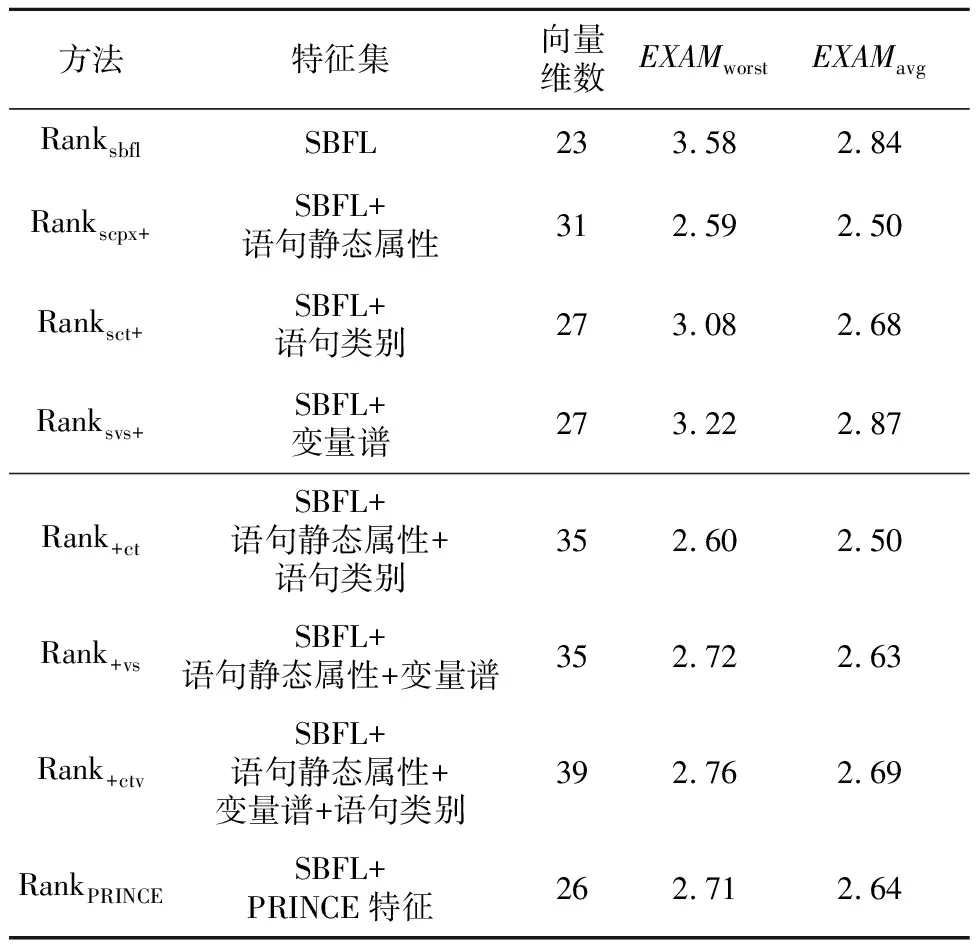
程序谱特征来源包括文献[13]的25个SBFL公式,再加上近年来被多次比较的一些SBFL公式。设定程序只包含单个故障,文献[8]从理论上证明了6组SBFL公式具有等价性质,因此移除了几个公式,最终选择第2节列出的23个SBFL公式为排序学习的程序谱特征。为加快学习算法收敛速度,将这些SBFL的可疑度值归一化到[0,1]。
结构复杂的代码中更容易隐藏错误。因此,本文将如表1所示的4种语句类别作为表征语句的特征,特征值为0或者1。为简化问题,并不执行重叠计数,任一语句只属于某一类,若循环(或return)语句包含条件判断,判其为循环(或return)语句。

Table 1 Structural types of statements
文献[19]也用到了语句类别,与本文做法有2点不同:(1)划分的类别不同;(2)类别被处理为一个实值,与单个SBFL可疑度值加权相加。
除程序谱、语句的结构化类别外,本文提出的基于排序学习的轻量方法,还可以集成语句静态属性、变量谱等特征。
4.1 程序语句的静态属性
一般来说,越复杂的程序语句(代码行),其导致软件出现故障的概率越大。代码复杂度与软件质量属性紧密联系,可分为内在复杂度和外在复杂度,软件的内在复杂度容易获取,外在复杂度获取代价大[23]。软件工程领域的代码复杂度研究成果繁多,常见的有代码行数、圈复杂度、类继承层次、模块扇入扇出、程序运行时间和可执行模块大小等。目前,还没有出现以语句为单位的代码复杂性测度,而本文的目标是定位到故障语句,因此设计了如表2所示的语句内在静态属性来表征语句复杂度。

Table 2 Static attributes for statement complexity
文献[10,15]都使用方法内参数数目和方法内类属性数目作为特征,前者还统计了方法内的运算符个数。位于同一方法中的语句并不能被方法级(或者类级)复杂度区分开来,因此本文在语句上计算此类代码复杂度。一般来说,逻辑运算符相比其它运算符,给语句带来更大的复杂度,因此本文拆分了运算符种类。无论全局变量,还是类属性,影响的程序功能点要多于方法参数,而方法参数影响的程序功能点又多于局部变量,将变量分成3种类型,更能提高语句复杂性的辨识度。至于语句块内定义的局部变量,并不明显增加代码的认知障碍,故而排除在外。
对于序号1~4的特征,同名变量不重复计数;
序号5的逻辑运算符限于&&、||和!,序号6不统计赋值运算符。不属于方法(函数)的语句,其序号1和2的特征值皆为0。C程序的语句只有全局变量,没有类的属性。长注释的相应代码应进行更多检查。若语句属于以下复合语句:assert、synchronized、do while、while、switch、throw、try catch、if、for,则其嵌套层次加1;
其它情形,嵌套层次不变。嵌套层次会递归计算。
如某个类的方法annotation有如下10行代码:
1 floatannotation(Configconfig,Typetype,floatr){
2 floatdesc=0,ac=0;/*(2,0,0,0,0,0,0,0,0,0,1)*/
3for(inti=0;i<10;i++){/*(0,0,0,0,0,2,0,1,0,0,0)*/
4desc+=cevf(config,r);/*(1,2,0,1,0,0,1,0,0,0,1)*/
5if((desc>100&&desc<200)‖
6 (desc>r&&ac 7ac=devf(type);/*(1,1,0,1,0,0,2,0,0,0,1)*/ 8 } 9returndesc+ac-pfVoc;/*(2,0,1,0,0,2,0,0,0,1,0)*/ 10 } 该方法有参数config、type和r,有顶层局部变量desc和ac(注意,第3行的i是定义在for语句块的局部变量),pfVoc为方法所属类的属性,cevf和devf是方法(函数)名称,则对应行的特征向量可从注释中观察到,11维特征向量中前7维属于语句静态属性(所列未包含注释字符数),后4维属于语句结构化类别。例如,第5、6行属于同一条语句,有2个顶层局部变量,2种关系运算符(&&和‖),2种其它运算符(<和>),属于条件语句,是for语句的从句,所以它的特征向量为:(2,1,0,0,2,2,1,0,1,0,0)。 归一化处理时,序号1~3的特征除以20,而序号4~7的特征除以10。 就作者所知,用于错误定位的语句级轻量特征,除语句类别[19]和变量谱[24]外,只有PRINCE的3个特征[21]:(1)语句的字符数; 变量仅限于全局变量、类属性、方法参数和顶层局部变量。变量谱定义为变量所属语句程序谱的平均值,表3是一个简单例子。 Table 3 Example of variable spectrum 某个类有方法ma和mb,attr是类的属性。方法ma有3条可执行语句(ma1,ma2和ma3),顶层局部变量为loca,参数为pa。方法mb有2条可执行语句(mb1和mb2),顶层局部变量为locb。测试套件有5个测试用例,3个成功,2个失败。依定义,变量loca在语句ma1、ma2、ma3出现过,其谱等于〈(2+3+1)/3,(1+1+2)/3,(1+2)/3,(1+1)/3〉=〈2,1.33,1,0.67〉。同理,locb的谱等于〈2,0.5,1,1.5〉,attr的谱等于〈1.5,1,1.5,1〉,pa只在ma1中出现,其变量谱等于ma1的程序谱〈2,1,1,1〉。 得到变量谱集合后,选择语句内最大可能引入故障的变量谱经归一化处理后当作语句的变量谱特征(4维向量),算法1描述了详细步骤。 算法1计算语句的变量谱特征 输入:Aep,Aef,Anp,Anf:语句的程序谱四元组; VARS:语句的变量集合; FT,PT:测试套件失败、成功测试用例数。 输出:变量谱特征。 fori=1 to|VARS| EFi=Aef[VARSi]/FT; EPi=Aep[VARSi]/PT; NPi=Anp[VARSi]/(Anp[VARSi]+Anf[VARSi]); NFi=Anf[VARSi]/(Anp[VARSi]+Anf[VARSi]); VARS排序结果赋值给L,排序依据为:EF降序优先,EP升序次之,NP降序再次之,NF升序最次之; var←L的首个元素; returnEF[var],EP[var],NP[var],NF[var]; 经算法1处理后,表3中4个变量依变量谱排序后,L={loca,attr,pa,locb},var=loca。因此,取loca的谱归一化向量为语句ma1、ma2和ma3的变量谱特征,取attr的谱归一化向量为语句mb2的变量谱特征。在计算语句的静态属性时,已经存储了各语句的变量信息,加之变量谱可由语句的程序谱转换,无须额外负担,因此,语句的变量谱特征计算代价极小。 Kim等人[24]首先提出了变量谱,将SBFL公式的程序谱用变量谱替换,计算可疑度后定位软件错误。与此不同的是,本文将变量谱作为表征语句的特征。 排序学习算法选用LibLinear的线性RankSVM,适合大规模样本和特征的数据集[25]。令PS为训练集,其元素由同一版本成对的故障语句与非故障语句构成(xi和xj)。RankSVM的优化目标[25]如式(3)所示: (3) 其中,w是样本(语句)的权向量,也就是RankSVM学习到的错误定位模型,C是模型的平衡因子。非故障语句判为错误语句,或者错误语句判为非故障语句,模型尽力减小这些误判引起的误差实数值,另外模型还必须保持泛化性,两者的平衡由C来调节。令某条语句的特征向量为x,则该语句的可疑度值等于w*x,*为内积运算。语句的w*x值越大,表示其包含故障的可能性更大。特征集除程序谱外,另包含语句静态属性,则x的维数等于23+8; 为验证本文方法的有效性,采用跨项目的方式构造错误定位模型。将项目按比例划分为训练集、验证集和测试集,同一项目的所有版本同时分配到某个子集。不同项目的可执行语句数大不相同,构造训练集时,从所有版本中统一取β条语句。构造验证集和测试集时,收集的所有可执行语句都被纳入。 RankSVM的优化目标无法最小化错误定位评价指标,利用排序模型的平衡因子C和验证集来调整错误定位性能误差。算法2描述了搜索最优错误定位模型的过程。 算法2搜索最优错误定位模型 输入:错误定位评价指标EXCHK; 输出:最优错误定位模型BestW。 将PRJS按比例随机划分训练集、验证集和测试集; TRAIN←从训练集每个版本中抽取β条可执行语句; VALID←从验证集抽取所有可执行语句; TEST←从测试集抽取所有可执行语句; EXCHKmin=1;//1是最大值 BestW=0,C=1; forj=1 toγ W←learn model inTRAIN; EXCHKnow←compute byWonVALID; ifEXCHKnow EXCHKmin=EXCHKnow; BestW=W; C=C/2; returnBestW; /*基于BestW计算当前测试集的性能*/ 所有实验在一台配置为Intel Core i7-8700 3.2 GHz CPU和16 GB 物理内存的计算机上完成,操作系统是Windows 10。 无论是包含单个故障的版本,还是多故障的版本,本文都采用EXAM来度量其错误定位性能,其定义如式(4)所示: EXAM= (4) 当有多条语句可疑度值相等时,最理想的情况下,检查其中一条语句就定位到故障,称为最优策略; 实验参数的设置,采用以下策略:针对算法2,参数β=100,γ=30;线性RankSVM的参数全部取默认值。实验共有22个项目,按5∶3∶3的比例随机划分为训练集、验证集和测试集,任意项目的所有版本只能处于同一子集内。参数β过小,模型适应性差,β过大,模型将拟合规模大的项目,绝大多数版本至少有100条可执行语句,故而设β=100。训练集选取可执行语句时,先取所有故障语句,再取故障语句的近邻,不足的部分,随机从其它类(C++、Java)或者函数(C程序)中选取。参数γ的取值可参考文献[25]。为减小训练集、验证集和测试集划分的随机性影响,算法2重复执行500次,后文实验数据是500次结果的平均值。 实验数据集来自于SIR、Pairika OpenCV、Defects4j和Bears。SIR软件项目基础资源库是软件错误定位领域知名的基准测试集[26],实验收集了实际故障的C语言项目space,有29个错误版本。OpenCV是一个轻量、高效、跨平台的计算机视觉和机器学习软件库。Pairika从OpenCV的7个模块中提取而得[27],它超过49×104行代码和11 129个测试用例,被构造为C++程序的故障诊断基准数据集。实验收集了OpenCV 331和OpenCV 340,共19个错误版本,所有错误皆为实际故障。Defects4j是软件测试领域广泛采用的基准数据集[28],其网站当前为2.0版本,实验收集了16个Java项目:Chart、Cli、Closure、Codec、Collections、Compress、JacksonCore、Gson、Csv、Databind、JacksonXml、Jsoup、JxPath、Lang、Math和Time,这些项目共有641个错误版本,所有错误皆为实际故障。通过持续集成的手段识别故障版本和修正版本,Bears[29]为自动化修复程序社区建立的一个基准数据集。实验收集了3个Java项目:FasterXML、traccar和AutoCar,共有64个错误版本,所有故障语句皆来源于实际编程。 在VirtualBox v6.1和Ubuntu 18.04环境下,执行SIR、Defects4j和Bears的测试用例,获得语句的程序谱。使用Gcov采集SIR的C程序的代码行覆盖数据。使用Cobertura采集Defects4j和Bears的Java程序的代码行覆盖数据。Pairika的测试用例执行结果在Windows 10环境下获取,使用开源软件OpenCppCoverage采集代码行覆盖数据。 有少部分代码中多条可执行语句排在一行,此时取可疑度最大值作为整行代码的可疑度值。很多故障代码属于缺失型,修正版里添加了正确语句,此时无法获取这些缺失语句的程序谱,本文实验采用以下简单做法:如果缺失语句后有代码,则以其后一行指代故障; Pairika、Defects4j和Bears的类非常多,为减少收集程序谱的时间,每个版本只记录最多30个文件的代码行覆盖数据。具体策略包括2个步骤:首先执行一遍所有测试用例,统计每个文件的被覆盖行数目; 在语句特征的采集与计算过程中,本文使用Eclipse的抽象语法树Parser解析源代码。在解析C程序和C++程序时,调用了CDT组件,解析Java程序时则调用了JDT组件。 为验证语句静态属性对错误定位模型的影响,定义特征集仅限23个SBFL公式的方法为Ranksbfl,集成程序谱和表2代码行静态属性的方法为Rankscpx+。表4对比了各故障定位方法在753个版本上的平均性能,最小值加粗表示。 对排序学习算法来说,EXAMworst以最坏策略为算法优化目标计算而得,EXAMavg以平均策略为算法优化目标计算而得。Ranksbfl和Rankscpx+的EXAM值如此,如非特别说明,后文其它排序学习算法的EXAM值亦如此。 以往小数据集或者人工注入故障数据集的部分研究成果并不受支持。如NaishO表现并不好,Wong2和Wong3更是糟糕。总体来看,比较23个传统SBFL方法,Dice、Jaccard、Anderberg、Goodman和Ochiai表现优异,Kulczynski1、Tarantula、Kulczynski2、Zoltar和DStar2也很不错。从表4可看出,相比表现最好的SBFL,Ranksbfl都有足够的竞争力。特征集加入语句静态属性后,Rankscpx+性能显著提高,EXAMavg减少了37.1%(SBFL的Ochiai最优),EXAMworst减少了22.6%(Ochiai最优)。 Table 4 Comparison of EXAM among sereval fault localization methods 表5列出了Rankscpx+与项目表现最佳的SBFL的性能比较。最佳SBFL列,未带加号表明多个SBFL同时取得最佳效果,带加号则只有一个SBFL取得最优性能,加号后是该SBFL的名称。 针对单个项目比较EXAMworst,除项目space、FastXML和Collections外,Rankscpx+都要比最优SBFL性能高; 这些项目的编程语言、测试用例数目、可执行语句规模和故障类型等都大相径庭,在验证集上获得最优的模型,在测试集上的性能并非最佳。表6的结果显示,分别以最坏策略和平均策略为优化目标,Ranksbfl的性能差别不大,Rankscpx+的性能更是接近。这也提示我们,增加合适的特征,从更多角度表征语句,错误定位模型的性能还会提升。 相比于传统SBFL方法,以及基于SBFL的搜索方法Ranksbfl,Rankscpx+的性能提升明显。将Rankscpx+的特征子集由语句静态属性替换为语句 Table 5 Performance comparison on a single project Table 6 Comparison of fault localization methods by two strategies 结构化类别(简称语句类别)、变量谱后,或者将语句类别和变量谱加入到Rankscpx+的特征集,表7展示了这些算法的性能。另外,RankPRINCE指集成23个SBFL公式和3个PRINCE特征的方法。 语句的3类轻量特征对错误定位模型性能都有帮助,语句静态属性表现最优,语句类别次之,变量谱再次之。从表7可观察到,变量谱的作用并不突出,集成SBFL和变量谱后,Rank+svs的EXAMavg值甚至比Ranksbfl的还差。3类轻量特征对 Table 7 Effect of three kinds of features on fault localization methods performance 语句内在复杂度的贡献作用存在负相关因素,导致特征集加上语句类别、变量谱后,Rankscpx+性能反而下降。即便集成SBFL、语句复杂度、语句类别和变量谱,Rank+ctv的性能还不如Rankscpx+的。或许这些特征拆得更细,能降低这种不利影响。相比RankPRINCE,Rankscpx+的特征集更丰富,性能也提高不少。 语句的特征获取时间复杂度低。表8是几个具规模代表性项目的时间开销,项目时间是其所有版本的平均值,单位为ms。在对应时间内,完成3项任务:解析源代码、计算语句特征向量和存储特征到文件。即使是OpenCV331这样规模的程序,获取特征的时间也不到1 s。 Table 8 Time overhead of feature acquisition 排序学习最优模型的求解时间开销也不大,表9是3个算法以EXAMworst为优化目标的错误定位模型搜索时间,单位为s。对应时间内,完成3项任务:读入特征集、划分训练集/验证集/测试集和求解最优错误定位模型。算法的时间为500次求解过程的平均值。 最优错误定位模型的训练在调试活动前完成。语句可疑度值的计算开销仅限于特征获取和模型特征与权向量线性内积运算,后者时间可忽略不计。因此,本文方法够轻量,能够实时地推荐可能出故障的语句序列。 Table 9 Time cost of solving the optimal model 数据集由22个项目组成,代码用3种流行的编程语言开发,各项目的故障并非人工注入,而是在实际开发项目时产生的,错误定位模型由跨项目形式训练而得。基于程序谱的搜索方法能帮助开发人员、自动修复软件并定位到故障语句,然而,源代码固有的故障相关信息被忽略,如何挖掘语句静态属性,研究提升错误定位性能的算法很有意义。本文设计了语句级代码复杂度的特征集。实验结果表明,集成程序谱和语句的这些静态属性后,通过排序学习算法获得的错误定位模型,能显著减少待排查的语句数目。语句其它2类轻量特征:结构化类别和变量谱,有助于改善SBFL搜索方法的性能,但比语句静态属性逊色不少,与其组合后,显现负面作用。实验还发现,一些在小数据集或者人工注入故障数据集上的结论并不成立。 实验数据集的项目大小不一,编程语言各异,故障类型多样,这些因素都制约了错误定位方法性能。扩充数据集,增加表达语句复杂性的静态属性,都是后续研究工作的重要内容。 主题党日活动交流发言8篇主题党日活动交流发言篇13月13日,东城区党史学习教育动员大会召开。市委
【活动总结】
日期:2022-12-23
2022年4月主题党日活动记录范文15篇2022年4月主题党日活动记录范文篇1一个崇尚阅读的民族,必然精神饱满、意气风发、活力四射。习近平总书记强调:“学习
【活动总结】
日期:2022-08-01
家乡赋 孙传志 今安康市,白河双丰镇,吾之家乡也。三环沃土,山水环抱。其北依山,山系五岭,山
【调研报告】
日期:2020-04-01
人教版二年级数学上册知识点汇总第一单元长度单位一、米和厘米1、测量物体的长度时,要用统一的标准去测量
【调研报告】
日期:2020-11-08
2022年党支部主题党日活动计划表序号活动时间活动方式活动内容12022年1月专题学习研讨集中观看2022年新年贺词,积极开展学习研讨交流。组织生活会组织党员认真对照党章...
【活动总结】
日期:2022-10-14
2022年2月份主题党日活动记录5篇2022年2月份主题党日活动记录篇1尊敬的党组织:在今年的开学初,本人积极参加教研室组织的教研活动,在学校教研员的指
【活动总结】
日期:2022-08-12
2017-2018学年队前教育1光辉历程一、劳动童子团1924——1927二、三十年代年的中国是一个
【法律文书】
日期:2020-06-23
平安校园建设方案“平安校园”创建工作,我们幼儿园全体教职员工一直把它当作头等大事来抓。领导高度重视,以“平安校园”创建活动为抓手,建立和规范校园安全工作机制
【规章制度】
日期:2023-11-02
医院最佳主题党日活动11篇医院最佳主题党日活动篇1 医院最佳主题党日活动篇2为隆重纪念中国共产党成立100周年,进一步巩固党的群众路线教育实践活动成果,切实
【活动总结】
日期:2022-10-29
主题党日活动记录202210篇主题党日活动记录2022篇12021年是中国共产党成立100周年,为广泛开展爱国主义宣传教育,铭记党的历史,讴歌党的光辉历程,
【活动总结】
日期:2022-08-02
新学期到了,我是一年级下册的小学生了。 上课的时候,我要认真学习,不做小动作,认真听讲。我要认真学习,天天向上,努力学习,耳朵要听老师讲课,眼睛要瞪得大大的看老...
【简历资料】
日期:2019-10-26
国行公祭,为佑世界和平钟声“国行公祭,法立典章。铸兹宝鼎,祀我国殇。”侵华日军南京大屠杀遇难同胞纪念
【简历资料】
日期:2020-11-28
作为我国特有的一项制度,信访制度的出现并长期存在不是偶然的,虽然一些法学专家认为信访制度具有“人治”
【职场指南】
日期:2020-02-16
2019年主题教育问题检视清单及整改措施根据主题教育领导小组办公室《关于认真做好主题教育检视问题整改
【求职简历】
日期:2019-11-08
国家开放大学电大专科《网络系统管理与维护》形考任务1答案形考任务1理解上网行为管理软件的功能【实训目
【职场指南】
日期:2020-07-17
民族团结的素材资料13篇民族团结的素材资料篇1研究进一步推进新疆社会稳定和长治久安工作。会议指出,要全面贯彻执行党的民族政策,把民族团结作为各族人民的生命线
【简历资料】
日期:2022-08-16
《红旗颂》朗诵词 女:晴空万里,红旗飘扬, 六十载风云,我们昂首阔步。 男:六十个春秋,
【职场指南】
日期:2020-02-16
为进一步加强xxx局工作的规范化、制度化建设,提高行政效能,规范议事程序,特制定本制度。一、会议形式1、局长办公会议由局长、副局长参加。由局长召集和主持。根据工作需要...
【求职简历】
日期:2019-07-30
当前,清河正处于在苏北实现赶超跨越基础上全面腾飞的战略机遇期,处于在全市率先实现全面小康基础上率先实
【简历资料】
日期:2020-03-17
影片深刻剖析了广西北海市公安局海西派出所原所长张枭杰蜕变堕落的轨迹。观看警示教育片后,做为一名党员教
【简历资料】
日期:2020-08-17
中国科学技术大学(UniversityofScienceandTechnologyofChina),位于安徽省合肥市,是中国科学院直属的一所以前沿科学和高新技术为主,兼有医学、特色管理和人文学科的综合
【其他范文】
日期:2023-01-03
以下是为大家整理的关于奥林匹克精神感悟4篇,供大家参考选择。奥林匹克精神感悟4篇【篇1】奥林匹克精神感悟奥林匹克精神顾拜旦学习目标:1.理清课文的思路,用体育精神来激发...
【其他范文】
日期:2022-12-26
改变自己和改变世界改变自己改变世界议论文800字在这纷繁嘈杂,喧嚣吵嚷的世界里,人们扮演着各自的角色。有些人一味地追名逐利、勾心斗角;有些人踏踏实实,愿当这
【节日庆典】
日期:2023-10-23
赖欣仪龙岩高岭土股份有限公司实践中随着社会主义现代化建设的推进,很多会计人员开始加强自身综合素质能力
【其他范文】
日期:2023-02-20
潘浩党的十八大以来,以习近平同志为核心的党中央高度重视“三农”工作,始终坚持以人民为中心的发展理念,
【其他范文】
日期:2023-01-24
本站为大家推荐下毕业感言感恩的心,感谢生活,命运虽有千万种,但是我想去勇敢的搏一搏。没有理想的人生是暗淡的,无味的。一生之中只有为了自己的梦想去拼搏的人生才是多彩...
【口号大全】
日期:2019-07-09
张宁(厦门航空有限公司,福建厦门361006)航线网络是航空公司赖以生存和发展的基础。构建布局合理、
【其他范文】
日期:2023-04-07
·特约专家论坛·鄱阳湖流域水资源生态安全状况及承载力分析夏军,刁艺璇,佘敦先,李淼,张勇奋,丁文璐,
【其他范文】
日期:2023-06-26
一、“3×6+1”执法模式开展情况 1、提高认识,加强组织保障。我局以“3×6+1”环境监察体系为平台,与市局要求保持高度一致,将全局的环境执法工作纳入到体系中,实现环境...
【汇报体会】
日期:2019-09-06
敬爱的党组织:2012年11月8日上午,万众瞩目的中国共产党第十八次全国代表大会拉开了序幕。党的十八大是在我国进入全面建成小康社会决定性阶段召开的一次十分重要的会议,大会...
【其他范文】
日期:2022-09-05
理论中心组学习总体国家安全观发言材料9篇理论中心组学习总体国家安全观发言材料篇1(八)深入学习贯彻中央以及省的重要会议和文件精神深入学习贯彻年度内中央以
【发言稿】
日期:2022-08-04
军转座谈会交流发言4篇军转座谈会交流发言篇1大家好,我叫贺丽,2015届选调生,来自康定市委组织部,现在省委编办跟班学习。今天,非常荣幸向大家汇报我的学习收
【发言稿】
日期:2022-10-27
12岁生日小寿星发言4篇12岁生日小寿星发言篇1各位来宾、各位朋友:大家好!今天,我们欢聚在这里,共同庆祝**十二周岁生日。首先,我代表**的父母以
【发言稿】
日期:2022-07-31
党内警告处分表态发言14篇党内警告处分表态发言篇1尊敬的各位领导、同事们:大家上午好!刚才会上宣布了党委关于我任职的决定,我首先衷心感谢党委的信任和
【发言稿】
日期:2022-09-13
党内警告处分党员讨论发言3篇党内警告处分党员讨论发言篇1大家好!作为新时期的一名大学生,认真学习、深刻领会、全面贯彻省党代会精神,是当前和今后一个时期重
【发言稿】
日期:2022-08-07
廉政大会总结发言稿7篇廉政大会总结发言稿篇1各位领导,同志们:根据会议安排,我就党风廉政建设工作做表态发言,不妥之处,请批评指正。一、提高认识,切实
【发言稿】
日期:2022-10-30
企业疫情风险控制方案2020新冠病毒肺炎疫情防控工作总结汇报3篇 关于新型冠状病毒感染的肺炎疫
【演讲稿】
日期:2020-02-27
被约谈的表态发言8篇被约谈的表态发言篇1各位领导、各位党员大家好:这天我能站在鲜红的党旗下,
【发言稿】
日期:2022-12-24
破冰提能大讨论个人发言4篇破冰提能大讨论个人发言篇1党史学习教育开展以来,我坚持读原著、学原文、悟原理。今天,根据会议安排,现在我就“学史明理”主题谈几点个
【发言稿】
日期:2022-10-09
巡察整改专题民主生活会总结发言8篇巡察整改专题民主生活会总结发言篇1按照区委统一部署和纪监委、巡察办关于召开党史学习教育专题组织生活会的工作安排,近期我紧贴
【发言稿】
日期:2022-10-12
中国行政区划调整方案(设想优秀民政部第二次行政区划研讨会会议内容一、缩省的意义与原则1.意义1)利于减少中间层次中国行政区划层级之多为世界之最,既使管理成本
【周公解梦】
日期:2024-02-20
学习周永开先进事迹心得体会【一】通过学习周永开老先生先进事迹后,结合自己工作思考,感慨万千。同样作为
【格言】
日期:2021-04-10
XX老干局推进党建与业务深度融合 发展工作情况的调研报告 党建工作与业务工作融合发展始终是一个充满生
【成语大全】
日期:2020-08-28
中国共产党第三代中央领导集体的卓越贡献 --------------继往开来铸就辉煌 【摘要】改
【成语大全】
日期:2020-03-20
全国中小学教师信息技术应用能力提升工程试题题库及答案(复习资料)一、判断题题库(A为正确,B为错误)
【格言】
日期:2020-11-17
党办公务员个人三年工作总结近三年来,本人在组织、领导的关心指导和同事们的团结协作下,尽快完成主角的转
【格言】
日期:2021-02-26
党的基层组织是党在社会基层组织中的战斗堡垒,是党的全部工作和战斗力的基础。加强和改进县级以下各类党的
【经典阅读】
日期:2020-01-22
七推理与集合1 期中考试数学成绩出来了,三个好朋友分别考了88分,92分,95分。他们分别考了多少分
【名人名言】
日期:2020-12-18
最新国家开放大学电大《现代教育原理》形考任务2试题及答案形考任务二一、多项选择题(共17道试题,共3
【成语大全】
日期:2020-07-20
和儿媳妇在一起幸福的句子1、假如人生不曾相遇,我还是那个我,偶尔做做梦,然后,开始日复一日的奔波,淹没在这喧嚣的城市里。我不会了解,这个世界还有这样的一个你
【格言】
日期:2023-11-10
关于三农工作重要论述心得体会3篇关于三农工作重要论述心得体会篇1习近平总书记指出:“建设现代化国家离不开农业农村现代化,要继续巩固脱贫攻坚成果,扎实推进乡村
【学习心得体会】
日期:2022-10-29
(呼和浩特铁路局大包电气化改造工程指挥部,内蒙古呼和浩特010050)摘要:文章介绍了福生庄隧道
【学习心得体会】
日期:2020-03-05
五个一百工程阅读心得体会13篇五个一百工程阅读心得体会篇1凡益之道,与时偕行。在全国网络安全和信
【学习心得体会】
日期:2022-12-07
城管系统警示教育心得体会9篇城管系统警示教育心得体会篇1各党支部要召开多种形式的庆七一座谈会,组织广大党员进行座谈,回顾党的光辉历程,畅谈党的丰功伟绩,
【学习心得体会】
日期:2022-10-09
发展对象培训主要内容10篇发展对象培训主要内容篇1怀着无比激动的心情,我有幸参加了__新区区委党校20__年第四期(区级机关)党员发展对象培训班。这次的学习
【培训心得体会】
日期:2022-09-24
扶眉战役纪念馆心得体会11篇扶眉战役纪念馆心得体会篇1有那么一段历史,低诉着血和泪的故事,慢慢地,随岁月老去;有那么一群人,放弃了闲逸的人生,辗转奔波中
【学习心得体会】
日期:2022-08-03
2022年全国检察长会议心得7篇2022年全国检察长会议心得篇1眼睛是心灵上的窗户,我们通过眼睛才能看到世间万物,才能看到眼前这美好的一切。拥有一双明亮的眼
【学习心得体会】
日期:2022-10-31
全面从严治党的心得体会800字7篇全面从严治党的心得体会800字篇1中国特色社会主义是我们党领导
【学习心得体会】
日期:2022-12-14
矫正心得体会6篇矫正心得体会篇1今天,是自己出监后第一次参加阳光中途之家组织的社区矫正方面的教育
【学习心得体会】
日期:2022-12-24
2月教师党员个人思想汇报敬爱的党组织:最近这一个月的时间对于我来说是极不平凡的,在这段时间里我认真学习了文化部网上党校的相关内容,经过长达40小时的
【教师心得体会】
日期:2023-10-15
2023年主题教育民主生活会六个方面个人检视、相互批评意见:1 理论学习系统性不强。学习习近平新时代中国特色社会主义思想不深不透,泛泛而学的时候多,深学细照的时候少,特...
【邓小平理论】
日期:2024-03-19
习近平总书记指出:“一个民族要走在时代前列,就一刻不能没有理论思维,一刻不能没有思想指引。”党的十八大以来,伴随着新时代中国特色社会主义思想在实践中形成发展的历程...
【三个代表】
日期:2024-03-19
xx镇20xx年县乡人大代表述职评议活动总结为响应县级人大常委会关于开展县乡两级人大代表述职评议活动,进一步激发代表履职活力,加强代表与人民群众的联系,提高依法履职水平...
【马克思主义】
日期:2024-03-19
“千万工程”是总书记在浙江工作时亲自谋划、亲自部署、亲自推动的一项重大决策,也是习近平新时代中国特色社会主义思想在之江大地的生动实践。20年来,“千万工程”先后经历...
【三个代表】
日期:2024-03-19
同志们:刚才,XX同志对市政协机关20XX年工作进行了很好的总结,很精炼,很到位,可以感受到去年机关工作确实可圈可点。XX同志宣读了表彰决定,机关优秀人员代表、先进集体代...
【邓小平理论】
日期:2024-03-18
区长,各位领导,同志们:汛期已经来临,我区城区防涝工作面临强大考验,形势不容乐观。年初,区城区防涝排渍指挥部已经召开专题调度会,修订完善应急预案,建立网格化管理机...
【马克思主义】
日期:2024-03-18
XX镇作风整治工作实施方案为深入贯彻落实党的二十大精神及省市区委深化作风建设的最新要求,突出重点推进干部效能提升,坚持不懈推动作风整治工作纵深发展,根据《关于印发《2...
【毛泽东思想】
日期:2024-03-18
xx市优化法治化营商环境规范涉企行政执法实施方案为持续优化法治化营商环境,激发市场主体活力和社会创造力,规范行政执法行为,创新行政执法方式,提升行政执法质效,着力解...
【毛泽东思想】
日期:2024-03-18
关于开展新一轮思想状况摸底排查工作的通知为深入贯彻落实关于各地开展干部职工思想状况大摸底大排查情况上的批示要求和改革教育第二次调度会议精神,有针对性做好队伍教育管...
【三个代表】
日期:2024-03-18
“中心的工作就是心中的事业”——公路养护中心主任典型事迹材料**,男,1976年6月出生,1993年参加工作,2000年4月调入**区交通运输局工作,大学本科学历,中共党员,现任**...
【马克思主义】
日期:2024-03-17
(2)运算符个数;
(3)加权变量数。这3个特征同样属于语句级静态属性。在PRINCE中,运算符包括10类:算术、逻辑、关系、位、指针、数组[]、赋值、复合赋值、sizeof、函数调用();
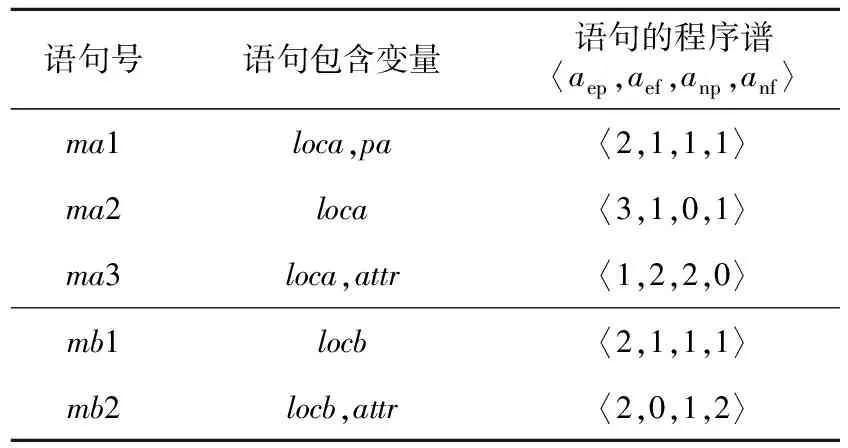
变量的权分为3类,基本数据类型的权为1,数组类型的权为数组元素个数,struct和class的权为其所有属性的权的累加值。为了与本文方法比较,将上述3个特征简称为PRINCE[21]特征。本文的实验数据有C++程序,许多项目采用新的Java、C++语法规则,基于这2个原因,本文采用微调方式计算PRINCE特征值。在计算操作符数时,除文献[21]统计的10类运算符外,另加入源代码解析工具能够统计的其它运算符。在计算加权变量数时,3类数据类型的权统一为1,因为指针、map、set、list等数据类型的元素个数获取代价非常大。文献[21]作者也承认,他们无法统计这些数据类型的元素个数。Java和C++类的对象属性值自然也难以累加。4.2 变量谱特征
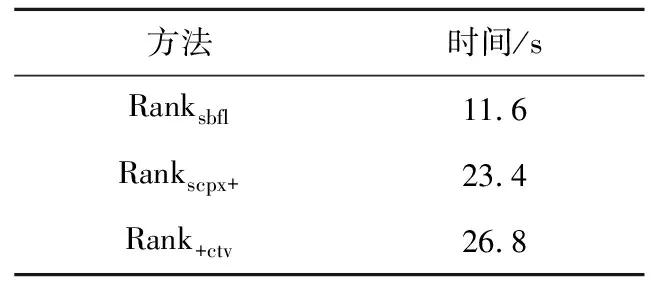
4.3 排序学习软件错误定位模型
另包含语句类别,则x的维数等于23+4;
另包含变量谱,则x的维数为23+4。
项目集合PRJS;
项目版本纳入训练集的语句条数β;
平衡因子C;
平衡因子搜索次数γ。
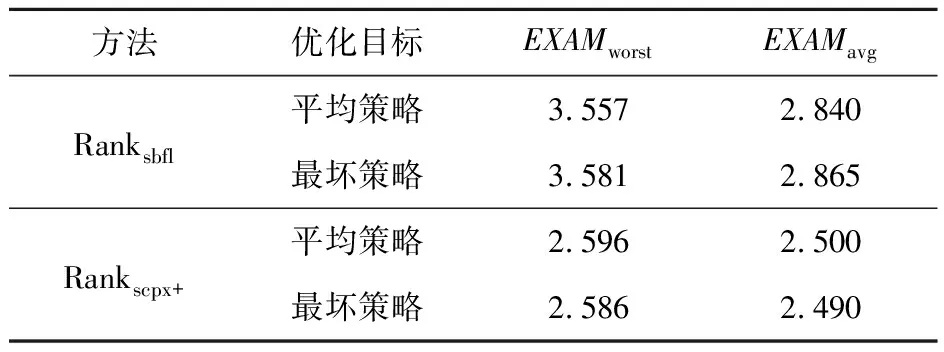
最坏的情况下,所有语句都检查完后才找到故障,此时性能记为EXAMworst;
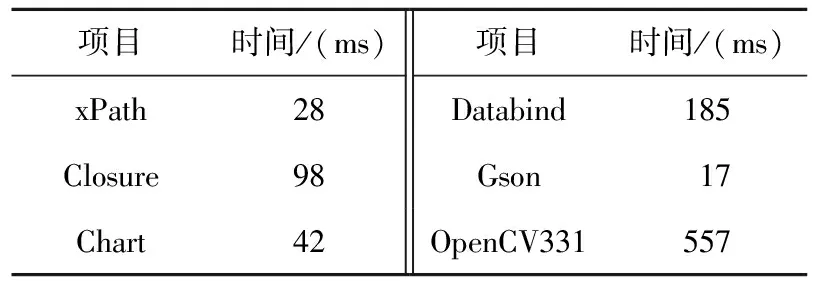
平均策略的性能EXAMavg为最优策略和最坏策略的平均值。5.1 实验数据集及语句特征计算
否则,以缺失语句前一行代码指代故障。
后续选择文件时,先加入带故障的文件,不足部分,优先挑选被覆盖行数最多的文件。5.2 本文方法与传统SBFL方法及基于SBFL的搜索方法对比
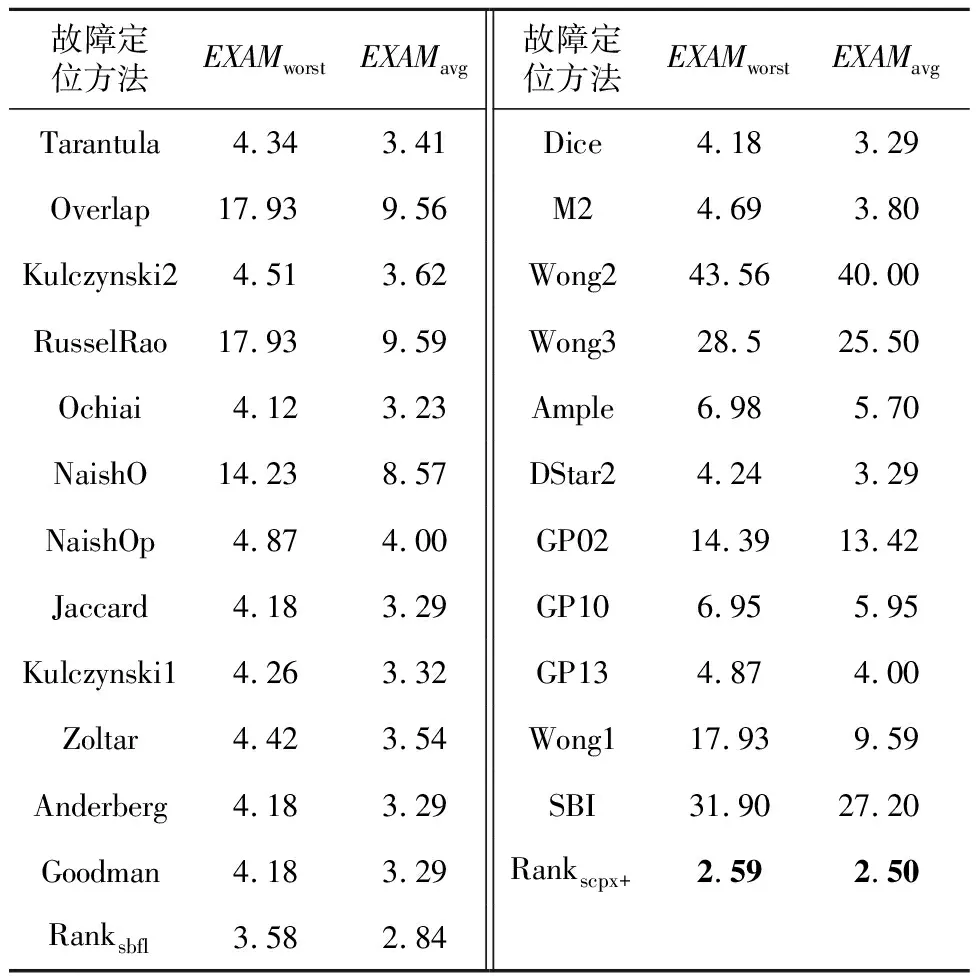
而以EXAMavg为评估标准,则Rankscpx+也在13个项目上胜出。不同编程语言的语句,特征计算方式有差别。数据集只有一个C项目space,它拉低了Rankscpx+的性能。5.3 结构化类别、变量谱和语句静态属性对比

 2024年主题教育民主生活会批评与自我批评意见(38条)(范文推荐)
2024年主题教育民主生活会批评与自我批评意见(38条)(范文推荐)
 2024年交流发言:强化思想理论武装,增强奋进力量(完整)
2024年度镇年度县乡人大代表述职评议活动总结
2024年交流发言:强化思想理论武装,增强奋进力量(完整)
2024年度镇年度县乡人大代表述职评议活动总结
 “千万工程”经验学习体会(研讨材料)
“千万工程”经验学习体会(研讨材料)
 2024年在市政协机关工作总结会议上讲话
2024年在市政协机关工作总结会议上讲话
 在全区防汛防涝动员暨河长制工作推进会上讲话提纲【完整版】
在全区防汛防涝动员暨河长制工作推进会上讲话提纲【完整版】
 2024年镇作风整治工作实施方案(完整文档)
2024市优化法治化营商环境规范涉企行政执法实施方案【优秀范文】
2024年镇作风整治工作实施方案(完整文档)
2024市优化法治化营商环境规范涉企行政执法实施方案【优秀范文】
 2024年度关于开展新一轮思想状况摸底排查工作通知(完整)
2024年公路养护中心主任典型事迹材料(完整文档)
2024年度关于开展新一轮思想状况摸底排查工作通知(完整)
2024年公路养护中心主任典型事迹材料(完整文档)